
Letting Things Slide: A New Trial Interface for Expressing Uncertainty
“How many spiral arms are in the image – is it two or three? Is that a disk viewed edge-on? I think so, but I’m not quite sure…” If you’ve interacted with Galaxy Zoo before, you may have asked yourself questions like these. Real galaxy images can be confusing. You may be uncertain!
Until now, you have always had to make a choice. There was no way to express uncertainty in your annotations. But now there is! Try it here.
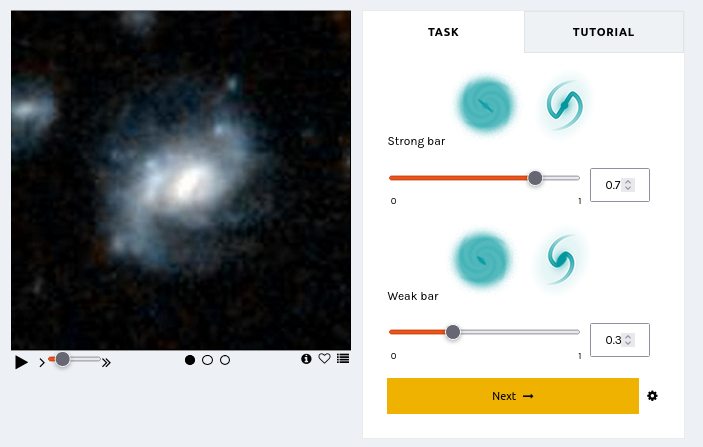
We are trialing a new experimental interface that lets you express your confidence in your annotations by dragging on a slider. This design is motivated by recent research indicating that we may be able to learn more, faster, by collecting annotator uncertainty [see this paper, this paper, this paper, this paper]. Allowing you to express your uncertainty by dragging a slider means that you – Zooniverse Friend – are providing more information with each click.
We believe this slider design might help us – through your support – discover more about galaxies, faster!
This is the second trial project we’re starting, adding to the Tags trial that Hayley introduced earlier on the blog. The big picture here is that we’re trying to think about how Galaxy Zoo could evolve in the coming years. As with any science project, we need to gather data and test our ideas.
Join in here and help us improve Galaxy Zoo.
We’ll run this trial for a short time – perhaps a couple of months – to gather your annotations and feedback. You can still use the current Galaxy Zoo that you know and (hopefully) love, at www.galaxyzoo.org.
Thank you for helping us,
Mike, Katie, and Ilia.
Machine Learning Messaging Experiment
Alongside the new workflow that Galaxy Zoo has just launched (read more in this blog post: https://wp.me/p2mbJY-2tJ), we’re taking the opportunity to work once again with researchers from Ben Gurion University and Microsoft Research to run an experiment which looks at how we can communicate with volunteers. As part of this experiment volunteers classifying galaxies on the new workflow may see short messages about the new machine learning elements. Anyone seeing these messages will be given the option to withdraw from the experiment’; just select the ‘opt out’ button to avoid seeing any further messages.
After the experiment is finished we will publish a debrief blog here describing more of the details and presenting our results.
This messaging experiment has ethics approval from Ben Gurion University (reference: SISE-2019-01) and the University of Oxford (reference: R63818/RE001).
Galaxy Zoo Upgrade: Better Galaxies, Better Science
Since I joined the team in 2018, citizen scientists like you have given us over 2 million classifications for 50,000 galaxies. We rely on these classifications for our research: from spiral arm winding, to merging galaxies, to star formation – and that’s just in the last month!
We want to get as much science as possible out of every single click. Your time is valuable and we have an almost unlimited pile of galaxies to classify. To do this, we’ve spent the past year designing a system to prioritise which galaxies you see on the site – which you can choose to access via the ‘Enhanced’ workflow.
This workflow depends on a new automated galaxy classifier using machine learning – an AI, if you like. Our AI is good at classifying boring, easy galaxies very fast. You are a much better classifier, able to make sense of the most difficult galaxies and even make new discoveries like Voorwerpen, but unfortunately need to eat and sleep and so on. Our idea is to have you and the AI work together.
The AI can guess which challenging galaxies, if classified by you, would best help it to learn. Each morning, we upload around 100 of these extra-helpful galaxies. The next day, we collect the classifications and use them to teach our AI. Thanks to your classifications, our AI should improve over time. We also upload thousands of random galaxies and show each to 3 humans, to check our AI is working and to keep an eye out for anything exciting.
With this approach, we combine human skill with AI speed to classify far more galaxies and do better science. For each new survey:
- 40 humans classify the most challenging and helpful galaxies
- Each galaxy is seen by 3 humans
- The AI learns to predict well on all the simple galaxies not yet classified
What does this mean in practice? Those choosing the ‘Enhanced’ workflow will see somewhat fewer simple galaxies (like the ones on the right), and somewhat more galaxies which are diverse, interesting and unusual (like the ones on the left). You will still see both interesting and simple galaxies, and still see every galaxy if you make enough classifications.

With our new system, you’ll see somewhat more galaxies like the ones on the left, and somewhat fewer like the ones on the right.
We would love for you to join in with our upgrade, because it helps us do more science. But if you like Galaxy Zoo just the way it is, no problem – we’ve made a copy (the ‘Classic’ workflow) that still shows random galaxies, just as we always have. If you’d like to know more, check out this post for more detail or read our paper. Separately, we’re also experimenting with sending short messages – check out this post to learn more.
Myself and the Galaxy Zoo team are really excited to see what you’ll discover. Let’s get started.
Scaling Galaxy Zoo with Bayesian Neural Networks
This is a technical overview of our recent paper (Walmsley 2019) aimed at astronomers. If you’d like an introduction to how machine learning improves Galaxy Zoo, check out this blog.
I’d love to be able to take every galaxy and say something about it’s morphology. The more galaxies we label, the more specific questions we can answer. When you want to know what fraction of low-mass barred spiral galaxies host AGN, suddenly it really matters that you have a lot of labelled galaxies to divide up.
But there’s a problem: humans don’t scale. Surveys keep getting bigger, but we will always have the same number of volunteers (applying order-of-magnitude astronomer math).
We’re struggling to keep pace now. When EUCLID (2022), LSST (2023) and WFIRST (2025ish) come online, we’ll start to look silly.

To keep up, Galaxy Zoo needs an automatic classifier. Other researchers have used responses that we’ve already collected from volunteers to train classifiers. The best performing of these are convolutional neural networks (CNNs) – a type of deep learning model tailored for image recognition. But CNNs have a drawback. They don’t easily handle uncertainty.
When learning, they implicitly assume that all labels are equally confident – which is definitely not the case for Galaxy Zoo (more in the section below). And when making (regression) predictions, they only give a ‘best guess’ answer with no error bars.
In our paper, we use Bayesian CNNs for morphology classification. Our Bayesian CNNs provide two key improvements:
- They account for varying uncertainty when learning from volunteer responses
- They predict full posteriors over the morphology of each galaxy
Using our Bayesian CNN, we can learn from noisy labels and make reliable predictions (with error bars) for hundreds of millions of galaxies.
How Bayesian Convolutional Neural Networks Work
There’s two key steps to creating Bayesian CNNs.
1. Predict the parameters of a probability distribution, not the label itself
Training neural networks is much like any other fitting problem: you tweak the model to match the observations. If all the labels are equally uncertain, you can just minimise the difference between your predictions and the observed values. But for Galaxy Zoo, many labels are more confident than others. If I observe that, for some galaxy, 30% of volunteers say “barred”, my confidence in that 30% massively depends on how many people replied – was it 4 or 40?
Instead, we predict the probability that a typical volunteer will say “Bar”, and minimise how surprised we should be given the total number of volunteers who replied. This way, our model understands that errors on galaxies where many volunteers replied are worse than errors on galaxies where few volunteers replied – letting it learn from every galaxy.
2. Use Dropout to Pretend to Train Many Networks
Our model now makes probabilistic predictions. But what if we had trained a different model? It would make slightly different probabilistic predictions. We need to marginalise over the possible models we might have trained. To do this, we use dropout. Dropout turns off many random neurons in our model, permuting our network into a new one each time we make predictions.
Below, you can see our Bayesian CNN in action. Each row is a galaxy (shown to the left). In the central column, our CNN makes a single probabilistic prediction (the probability that a typical volunteer would say “Bar”). We can interpret that as a posterior for the probability that k of N volunteers would say “Bar” – shown in black. On the right, we marginalise over many CNN using dropout. Each CNN posterior (grey) is different, but we can marginalise over them to get the posterior over many CNN (green) – our Bayesian prediction.

Read more about it in the paper.
Active Learning
Modern surveys will image hundreds of millions of galaxies – more than we can show to volunteers. Given that, which galaxies should we classify with volunteers, and which by our Bayesian CNN?
Ideally we would only show volunteers the images that the model would find most informative. The model should be able to ask – hey, these galaxies would be really helpful to learn from– can you label them for me please? Then the humans would label them and the model would retrain. This is active learning.
In our experiments, applying active learning reduces the number of galaxies needed to reach a given performance level by up to 35-60% (See the paper).
We can use our posteriors to work out which galaxies are most informative. Remember that we use dropout to approximate training many models (see above). We show in the paper that informative galaxies are galaxies where those models confidently disagree.
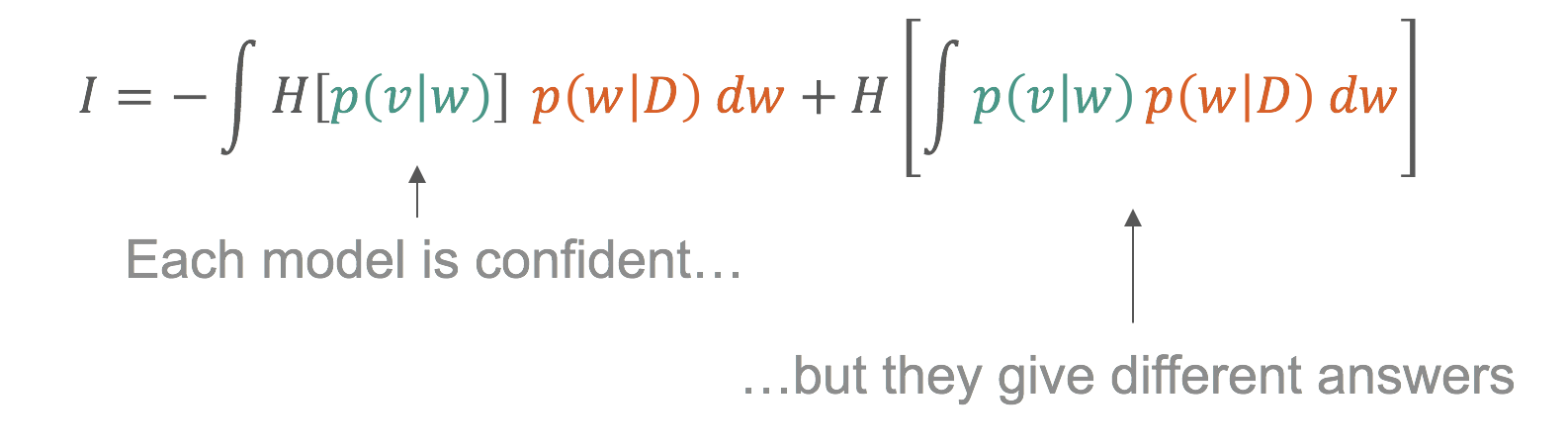
This is only possible because we think about labels probabilistically and approximate training many models.
What galaxies are informative? Exactly the galaxies you would intuitively expect.
- The model strongly prefers diverse featured galaxies over ellipticals
- For identifying bars, the model prefers galaxies which are better resolved (lower redshift)
This selection is completely automatic. Indeed, I didn’t realise the lower redshift preference until I looked at the images!
I’m excited to see what science can be done as we move from morphology catalogs of hundreds of thousands of galaxies to hundreds of millions. If you’d like to know more or you have any questions, get in touch in the comments or on Twitter (@mike_w_ai, @chrislintott, @yaringal).
Cheers,
Mike
Machine Learning Paper Accepted!
Exciting News from Manda Banerji on the Machine Learning paper:
Hi Everyone!
This is to let you all know that the Galaxy Zoo machine learning paper has now been accepted for publication in the Monthly Notices of the Royal Astronomical Society journal. The final version of the paper is at http://arxiv.org/abs/0908.2033. You can read all about the paper in my previous blog post at http://blogs.zooniverse.org/galaxyzoo/2009/08/05/latest-galaxy-zoo-paper-submitted/.
The paper has already attracted a lot of interest from the computer science community demonstrating that your classifications are proving useful and interesting to non astronomers as well!
Machine learning paper now available
Just a quick note that Manda’s submitted paper on machine learning is now available on astro-ph.
