
New paper: Galaxy Zoo and machine learning
I’m really happy to announce a new paper based on Galaxy Zoo data has just been accepted for publication. This one is different than many of our previous works; it focuses on the science of machine learning, and how we’re improving the ability of computers to identify galaxy morphologies after being trained off the classifications you’ve provided in Galaxy Zoo. This paper was led by Sander Dieleman, a PhD student at Ghent University in Belgium.
This work was begun in early 2014, when we ran an online competition through the Kaggle data platform called “The Galaxy Challenge”. The premise was fairly simple – we used the classifications provided by citizen scientists for the Galaxy Zoo 2 project and challenged computer scientists to write an algorithm to match those classifications as closely as possible. We provided about 75,000 anonymized images + classifications as a training set for participants, and kept the same amount of data secret; solutions submitted by competitors were tested on this set. More than 300 teams participated, and we awarded prizes to the top three scores. You can see more details on the competition site.
Since completing the competition, Sander has been working on writing up his solution as an academic paper, which has just been accepted to Monthly Notices of the Royal Astronomical Society (MNRAS). The method he’s developed relies on a technique known as a neural network; these are sets of algorithms (or statistical models) in which the parameters being fit can change as they learn, and can model “non-linear” relationships between the inputs. The name and design of many neural networks are inspired by similarities to the way that neurons function in the brain.
One of the innovative techniques in Sander’s work has been to use a model that makes use of the symmetry in the galaxy images. Consider the pictures of the same galaxy below:

A galaxy from GZ2, shown both with no rotation (left) and rotated by 45 degrees (right).
From the classifications in GZ, we’d expect the answers for these two images to be identical; it’s the same galaxy, after all, no matter which way we look at it. For a computer program, however, these images would need to be separately analyzed and classified. Sander’s work exploits this in two ways:
- The size of the training data can be dramatically increased by including multiple, rotated versions of the different images. More training data typically results in a better-performing algorithm.
- Since the morphological classification for the two galaxies should be the same, we can apply the same feature detectors to the rotated images and thus share parameters in the model. This makes the model more general and improves the overall performance.
Once all of the training data is in, Sander’s model takes images and can provide very precise classifications of morphology. I think one of the neatest visualizations is this one: galaxies along the top vs bottom rows are considered “most dis-similar” by the maps in the model. You can see that it’s doing well by, for example, grouping all the loose spiral galaxies together and predicting that these are a distinct class from edge-on spirals.

From Figure 13 in Dieleman et al. (2015). Example sets of images that are maximally distinct in the prediction model. The top row consists of loose winding spirals, while the bottom row are edge-on disks.
For more details on Sander’s work, he has an excellent blog post on his own site that goes into many of the details, a lot of which is accessible even to a non-expert.
While there are a lot of applications for these sorts of algorithms, we’re particularly interested in how this will help us select future datasets for Galaxy Zoo and similar projects. For future surveys like LSST, which will contain many millions of images, we want to efficiently select the images where citizen scientists can contribute the most – either for their unusualness or for the possibility of more serendipitous discoveries. Your data are what make innovations like this possible, and we’re looking forward to seeing how these can be applied to new scientific problems.
ATLAS data and Radio Galaxy Zoo: more details
(This post was co-written with Minnie Mao, an RGZ science team member and postdoc at the National Radio Astronomy Observatory in New Mexico.)
Thanks again for starting your work on the new images from the ATLAS survey! We wanted to talk more about how/why these images differ from the existing FIRST images, including details on the telescopes, survey data, and our science goals.
1. What kind of telescopes are used to take the new images?
The radio data in the new images is from the Australia Telescope Compact Array (ATCA), which is located in rural Australia outside the town of Narrabri. The ATCA has 6 separate radio dishes, each 22 meters in diameter. The Very Large Array (VLA), which took the FIRST images, has 27 dishes which are each 25 meters apiece; this means that ATCA has about 1/5th the collecting area of the VLA, and is less sensitive overall. The ATCA can still detect very faint radio objects, but they typically have to take longer exposures (integrate) than the VLA does.

The six radio dishes of the ATCA, located outside of Narrabri, NSW, Australia. Image courtesy CSIRO/Ettore Carretti.
The size of the arrays for the two telescopes is also different. The ATCA has a maximum baseline of 6km, which means that at 20cm (the wavelength used in RGZ images) you have a resolution of ~9 arcsec. This sets the smallest size of structures seen in the radio contours. The VLA has a longer maximum baseline of 36km, which means at 20cm you have a resolution of ~1.2arcsec. The configuration used for the FIRST images in RGZ has a resolution of about 5 arcsec, which is about twice as small as that in the new ATLAS data.
Finally, one of the biggest differences between the two telescopes comes from the arrangement of the dishes, not just their maximum size. The VLA is in a Y-shape which means imaging can be done in relatively short exposures, called ‘snapshots’. The ATCA is in a linear configuration running from east to west. Imaging with the ATCA requires observations over a large range of times so that observations are taken at a variety of earth rotation positions (filling the uv-plane). A full synthesis image with the ATCA requires 12 hours of observing.
The infrared data comes from the SWIRE survey carried out with the Spitzer Space Telescope. Spitzer is an infrared observatory launched by NASA in 2003 and is still operating today. One big difference between Spitzer and WISE is their relative sensitivities and field of view; Spitzer has a bigger mirror than WISE, but a much smaller field of view. Spitzer was designed mostly to study individual objects in detail and at very high sensitivity. WISE, on the other hand, was a survey telescope designed to sweep across the entire sky several times and detect all the infrared objects it could. So instead of mapping the whole sky, Spitzer carried out smaller observations of specific fields.
Spitzer had cameras that could image at a wide range of infrared wavelengths; the new images use Spitzer’s lowest-wavelength filter (3.6 microns) on the IRAC camera. This is almost exactly the same wavelength used for the WISE images (3.4 microns), so these are directly comparable. These near-infrared wavelengths are sensitive to emission from older/cooler stars, warm dust, and light from accretion disks that may surround black holes within galaxies.
2. Where in the sky were these new images taken?
The new images come from two fields in the Southern Hemisphere, called the Chandra Deep Field South (CDF-S) and the European Large Area ISO Survey South-1 (ELAIS-S1). If you know your constellations, these lie near Fornax and Phoenix, respectively.
These fields were chosen specifically so there weren’t bright radio sources in/near the fields. Moreover, these fields have tonnes of ancillary data! The CDF-S is one of the most intensely observed fields in the sky, with deep data from world-class telescopes from radio to gamma-ray! The CDFS (proper) is actually a MUCH smaller region than the ATLAS project observed… but the generally larger field-of-view from the radio telescope enabled a decent chunk of sky to be observed. This is critical to avoid problems such as cosmic variance.

A panoramic view of the near-infrared sky shows the distribution of galaxies beyond the Milky Way. SWIRE covers six small fields; two at the bottom right (Chandra-S and ELAIS-S1) are the ones now included in Radio Galaxy Zoo. Image courtesy NASA/T. Jarrett.
Deep fields like CDF-S and ELAIS-S1 enable statistical properties of galaxies to be determined over cosmic time, and of course understanding how galaxies have formed and evolved is probably the most important extragalactic astronomy question 🙂 These sorts of wide + deep observations also are great for discovering the ‘unknown’… 🙂
3. Why do these images look different than the ones already in RGZ?
This one is fun!! Mostly due to the VLA’s Y-shaped configuration, image artefacts tend to be hexagonally shaped (like a six-sided snowflake). Conversely, ATCA artefacts tend to look like radial spokes.
The ATLAS images also have ~10 arcsec resolution whereas the FIRST images have 5 arcsec resolution so the FIRST images might appear more ‘detailed’.
Both the ATLAS and SWIRE data are much more sensitive than the FIRST/WISE data because the telescopes integrated on this small part of the sky for much longer.
4. Why does the RGZ science team want to cover these fields?<
One reason is that ATLAS is what's called a "pathfinder" mission for an upcoming survey called EMU. EMU will use another telescope in Australia, named ASKAP, to do a deep survey over the entire sky. This is the best of both worlds, combining the sensitivity of ATLAS with the sky coverage of FIRST, and will provide ~70 million radio sources! A pathfinder mission like ATLAS is a smaller version which tests things like hardware, data reduction, and feasibility of larger surveys. We plan on asking citizen scientists to help with the EMU data as well, and so starting on the ATLAS images is a critical first step.
Since the area covered in these images is also much, much smaller than the FIRST survey, it was possible for small groups of astronomers to visually go through and cross-match the radio and IR emissions. Those results were published several years ago (led by RGZ science team member Ray Norris). Getting your results for the same set will help us to calibrate the new data from FIRST, which has many more galaxies and for which we don’t have the same information yet. We also want to see what new objects are left to be discovered in ATLAS (giant radio galaxies, HyMORS, WATs, etc.) that astronomers may have missed!
New ATLAS images for Radio Galaxy Zoo
Dear Radio Galaxy Zoo volunteers,
Thanks again for all your help so far in classifying radio galaxies through RGZ. We’re rapidly approaching our 1 millionth classification, probably by the end of this week (Jan 15-17) at the current rate. Don’t forget that we’ll be awarding prizes!
In the meantime, we’re excited to announce that we’ve just finished processing a new set of images for RGZ. There are 2,461 new images in total: the radio images are from a survey named ATLAS, carried out by the ATCA telescope in Australia. The corresponding infrared images come from the Spitzer Space Telescope as part of a survey named SWIRE.
Due to the differences in telescopes (ATCA has fewer dishes and a different arrangement of them than the VLA, while Spitzer has a much bigger mirror than WISE) and the depths of the two surveys, the data will look a little bit different. If you’ve done lots of classifications on Radio Galaxy Zoo already, you may notice more elongated radio beams in the ATLAS data, as well as a slightly larger size of the smaller unresolved noise spots. ATLAS can also detect fainter objects than the FIRST survey.
The new SWIRE infrared images have about twice the angular resolution of WISE (it can separate objects down to 3 arcseconds apart) and are more than 20 times as sensitive. That means you’ll likely see more infrared objects in the new images, and might have more choices for likely host galaxies for radio emission.

An example of one of the new ATLAS/SWIRE images for Radio Galaxy Zoo, as seen in Talk. From left to right: radio contours, infrared overlaid with radio, infrared only.
Since the images are mostly similar, the task for RGZ hasn’t changed (in fact, the original tutorial image was from ATLAS data). We’re still asking you to pick out individual radio components (or groups of components) and match them to their IR host galaxies. The new images will be randomly mixed in with the older images; you should see an ATLAS image every 6th or 7th classification, on average. If you’re curious whether a galaxy you’ve just classified is in ATLAS, the easiest way is to look at it in Talk: the new galaxy names will begin with a “C” (eg, “CI3180”) and will have declinations that are negative (eg, -27.782) showing that they’re in the Southern Hemisphere.
We’ll post a longer blog post very shortly with more information on ATLAS, SWIRE, and what we’re hoping to learn from these new images. In the meantime, please post here or on Talk if you have any questions!
And keep up the classifications in the next few days — hopefully you can be our 1 millionth image!
Radio Galaxy Zoo: “gold standard” images and improving our calibration
First off, the science team for Radio Galaxy Zoo wants to thank our volunteers for their continued clicks, discussion on Talk, and continued participation in the project. As of today, we have 892,582 classifications on RGZ and over 45,000 subjects completed from the FIRST-SDSS sample. We absolutely could not do this without you, and we’re working hard on turning the data into interesting science.
We want to let you know of some particular galaxies that will be appearing slightly more often in the interface. One of the things I’ve been working on for Radio Galaxy Zoo over the last month is finding better and smarter ways of combining clicks from independent classifiers into the “final answer” for each galaxy. For past Zooniverse projects, we’ve been able to do this using relatively simple methods – users are weighted a little bit by their consistency with other volunteers, but the final data product is mostly just the vote fractions for various tasks. However, the task in RGZ is a bit more complex, and the simpler methods of combining classifications are proving very difficult. In order to accurately combine the information each volunteer gives us, we need to establish a bit more common ground than we currently have.
To calibrate the clicks across all citizen scientists, we need to look at galaxies that the same people have done. The science team has started this by labeling the correct morphologies (to the best of our abilities) for a smaller, “gold standard” sample. We use these as seed weights in our data reduction – that lets us calibrate users who have done the gold standard galaxies. These results are propagated outward to the full sample by looking at other galaxies done by both calibrated and uncalibrated users, and so on. Kind of like pulling ourselves up by the bootstraps. 🙂

Result of the science team classification of a small sample of 100 RGZ galaxies. The height of the bar represents how well a particular science team member agreed with the others. As a group, the results show very good consistency overall, near 90%. Using the results from this sample, we can apply similar calibrations to the tens of thousands of galaxies that RGZ citizen scientists are helping us with.
What we’re missing right now, though, are galaxies that lots of citizen scientists have jointly classified. Since each galaxy is retired after 20 people classify it, the chances of seeing a particular galaxy is pretty low. Some members of the science team, including myself, recently sat down with a sample of 100 galaxies taken from a combination of random selection and ones you’ve identified on Talk as having interesting or non-trivial morphologies (bent jets, triple systems, giants, no IR counterparts, etc). These is what we’d like to use for calibration. However, only about a dozen users so far have done enough of this sample to give us enough data for calibration.
So, in order to help the accuracy of the data pipeline, we’ve chosen 20 “gold standard” galaxies that will eventually be shown to all volunteers. They won’t all be in one bunch (you should see one every five subjects or so) and you shouldn’t see any galaxies that you’ve classified before. We’ll label the galaxies on Talk – look for the hashtag #goldstandard. I hope that another positive outcome will be users getting to discuss interesting features in galaxies that they haven’t come across before. After you’ve done all 20 galaxies in the sample, your future classifications will be randomly selected as usual.

ARG0001e8e – a very nice core + hotspot system, and slightly challenging morphology to classify. This is one example of the 20 “gold standard” galaxies we’re trying to have everyone in RGZ classify.
Please let us know on Talk if you have any questions about this, and I’ll be happy to discuss it further. Thanks again for all of your help – we hope this will let us produce a more accurate RGZ product and science papers in the coming year!
Finished with Galaxy Zoo: UKIDSS!
I’m happy to announce that thanks to the hard work of more than 80,000 volunteers, we’ve recently completed classifying the infrared images of galaxies taken from the UKIDSS survey! There were more than 70,000 images of galaxies on the site that you helped to classify; once the data are reduced, one of our main goals is to compare your classifications to those from the Galaxy Zoo 2 project and study how morphology changes as a function of the wavelength in which those galaxies are observed. Melanie Galloway, a PhD student at the University of Minnesota, will be focusing on these this summer as part of her thesis work.
![]()
Some early results have shown that, as we predicted, features like galactic bars are often more prominent in the infrared. Below is a nice example of this phenomenon: the image is of the same galaxy (SDSS J115244.84+054059.1). In the optical image on the right (from GZ2), you can see a spiral galaxy with lots of star-formation, but the clumpy morphology of the gas clouds can hide the shape of the bar in the galaxy. In the UKIDSS image on the right, the blue gas clouds from star formation aren’t picked up in the infrared, and the stellar bar is much more clearly visible. This is supported by your classifications: the probability of a bar jumps from just 25% in GZ2 to 67% in GZ:UKIDSS.

Two images of the same galaxy; the infrared UKIDSS image on the left, and the optical SDSS image on the right. The strong bar in the galaxy is much more obvious in the infrared image.
This marks the third set of galaxy images we’ve completed since the relaunch of Galaxy Zoo in 2012 (following the high-redshift CANDELS images from Hubble and the artificially-redshifted images from FERENGI). There are still tens of thousands of galaxies from the SDSS left to classify in Galaxy Zoo, though, and we’ll be adding new sets of images in the coming months. Thanks again for your help, and we’ll report on the results of the UKIDSS data as it comes in!
Images and artifacts in Galaxy Zoo: UKIDSS
Last October, Galaxy Zoo began including new images from the UKIDSS survey on the main site. These are many of the same galaxies that were classified in GZ2, but the images come from a completely different telescope and a different wavelength — the infrared. While there’s a lot of science we’ll be able to do comparing galaxy morphologies at different wavelengths, many volunteers have noticed artifacts (features that aren’t real astronomical objects) in the UKIDSS images that can look very different from what you’re used to seeing in the SDSS or Hubble images:
- green squares
- rings and ghosts
- grid patterns and speckles
These are only a small percentage of the images we’re looking at, but it’s important to identify them and try to separate them cleanly from the galaxies we’re classifying. So here’s our “spotter’s guide” to UKIDSS image artifacts.
Green squares
All of the UKIDSS images you see in Galaxy Zoo are what we call “artificial-color” — we use images captured by the telescope’s infrared detector, and then combine the different infrared wavelengths into a single color image. For our images, we use data from the Y-band filter (1.03 microns) for the red channel, J-band filter (1.25 microns) for green, and K-band (2.20 microns) for the blue channel.
The images in Y, J, and K were taken at separate times and with different detectors and filters. So for changes in either the camera or the sky, these will often only show up in one color in the GZ images.
Some users have identified a persistent pattern in the images that looks like four little green pixels arranged in a square (looks a little like the UKIDSS logo!). This is from the J-band images.
The origin of the squares comes from the way that UKIRT processes data. Each patch of the sky is imaged in multiple exposures, and then these exposures are combined to get the final, deeper image. So each pixel in the image comes from four different locations on the detector. In the case of J-band images, the telescope actually took 8 different exposures during the dither pattern. For a few of the observing runs, the telescope lost the guidestar which keeps it positioned at the correct location; that means that the expected number of counts at the position of a bright star is lower due to the bad frame in the interlaced data. Normally, the software algorithms in UKIDSS drop the bad frames and correct for this effect; as GZ volunteers have identified, though, there are some cases where it didn’t work perfectly. (Many thanks to UKIDSS Survey Scientist Steve Warren at Imperial College London for his help in explaining this phenomenon.)
Since the exposure pattern is in a square, the bad pixels will show up where there’s a bright star and one of the four frames is bad (meaning counts are lower than they should be). That’s the origin of the pattern showing up in some images.

The four green dots in a square pattern on the left side of the image are from a single bad frame in the J-band processing of the data.
Grid patterns
As mentioned above, the telescope takes multiple exposures for each part of the sky that it images. To improve this, for some of the bands, it images the same part of the sky for a second round, but offsets the location of these by either an integer or half-integer pixel. The reason for this is so we can improve the angular resolution of the telescope – that is, distinguishing small features in the galaxy that are normally blurred out by either the Earth’s atmosphere or the limiting power of the telescope itself.
In the final data products, images from these offset frames are combined onto a fixed pixel scale in a process called interleaving. In some sources (bright ones especially), the gridding isn’t perfect and you can see some of the scale for this in the images.

Gridding pattern (the square pixels at the center of the bright blue star) are due to the interleaving process of combining data.
Green ghosts
Another feature people have spotted are what have been called “ghosts”: these can be either regular or irregularly shaped objects appearing in a couple specific colors. There might be multiple causes for these, but one of the most common is the presence of an actual contaminant (a speck of dust, for example) that got into the optics of the telescope. Since the telescope isn’t designed to focus on nearby objects, the point source is distorted, usually into a ring-like shape. The color of these images, like the green squares, depends on what band they were imaged in; red for Y-band, green for J-band, or blue for K-band.
Here’s one example: you can see the green and blue ring to the right of the galaxy in the color GZ image. The raw data (in black and white) shows the same ring in multiple locations, which tells us that it remained in the same position on the detector, but appears several times as the telescope moves over the sky.

This image has an artifact (blue/green ring) to the right of the spiral galaxy AGZ00077ec.

The raw Y-band image of the data shows the same artifact appearing multiple times as the telescope tracks across the sky.
Result
We hope this has been useful, but please continue to discuss these in Talk and on the forums; particularly if there are any artifacts that impede your ability to make a good galaxy classification. Happy hunting, and thanks for continuing to participate with us on Galaxy Zoo.
A Galaxy Zoo update for 2014
Exciting news for everyone who has been helping to classify (and discuss) the new images added to Galaxy Zoo just a couple of months ago. Back in October, we added two new sets of images to Galaxy Zoo: infrared images of galaxies from the UKIDSS survey, and optical images of galaxies that were processed to make them artificially redshifted (appear as if they were much further away). The second set is critically important for the data from GZ: Hubble and the CANDELS project; we need this to properly calibrate the classifications for effects like changing resolution and surface brightness as a function of distance.

An example of an artificially-redshifted galaxy from Galaxy Zoo.
As of last week, we’re excited to announce that the classifications of the artificially redshifted galaxies have been finished! They’ll now be retired from active classification, and we’re excited to start working on the analysis right away to enable the science we want to do on high-redshift galaxies. In the meantime, please keep your classifications coming for both the SDSS and UKIDSS images on Galaxy Zoo. There’s plenty left to do, although we’re getting closer with your help!
Radio Galaxy Zoo: New tools in Talk
For Zooniverse projects, the science teams have always been really impressed by the users who actively participate in Talk and engage in close inspections and discussions. This is especially true for our newest project, Radio Galaxy Zoo, and the number of excellent questions about larger structure for the powerful radio jets has spurred us to add some new tools to the Talk interface.
The new tools we’ve set up (with the invaluable help of Zooniverse developer Ed) show images of the galaxies and their associated radio jets from other surveys. New images include radio observations from the NRAO VLA Sky Survey (NVSS) and optical images from the Sloan Digital Sky Survey (SDSS). We’ve also included direct links to the FIRST (radio) and WISE (infrared) datasets that we use to make the classification images in the first place.
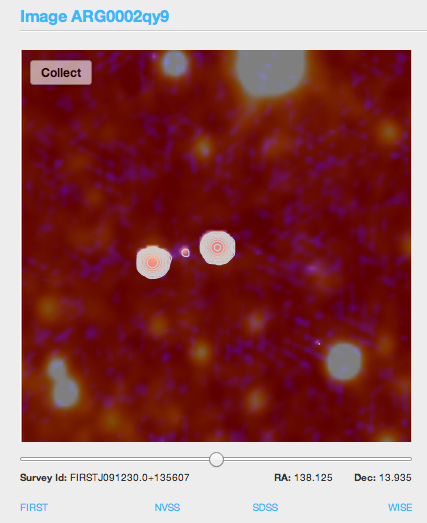
The new tools in RGZ now link to four catalogs (FIRST, NVSS, SDSS, and WISE) for each galaxy along the bottom of each image. FIRST and NVSS are radio surveys, SDSS is optical, and WISE is infrared.
Radio images with wider fields of view, such as NVSS, help to identify structures that may extend beyond the boundaries of the standard RGZ image. These include many of the images being labeled as #overedge in Talk. The NVSS images were taken using the same telescope (the Very Large Array in New Mexico) and at the same wavelength at the FIRST radio images. The main difference is the spacing of the telescopes used to take the observation. NVSS images have a much larger beam size, and are better at resolving large and extended structures. FIRST has a smaller beam size and are more sensitive to compact structures with very accurate positions. FIRST is also about 2.5 times more sensitive than NVSS.
By looking at the NVSS images, both RGZ volunteers and scientists have been able to work together and find potentially new examples of giant radio galaxies in these surveys. Larry Rudnick (@DocR) has started a great discussion on Talk, and we’re still identifying more as the project continues.

RGZ image ARG0002gt4, as seen in three of the surveys accessible in the new tools. The wide-field radio NVSS image of the jets is on the left; in the middle is the radio FIRST image, showing the better-resolved galaxy core, and on the right is the infrared WISE image showing the host galaxy. Image from Larry Rudnick (UMN).
We’ve also added links to the infrared and optical catalogs that show the galaxies themselves. The infrared images that we show in RGZ come from the WISE spacecraft, an orbiting infrared telescope that carried out an all-sky survey. The new link shows you infrared images of the galaxy in four different infrared bands (3.4, 4.6, 12, and 22 microns), as opposed to the single 3.4 micron image we normally show. Detecting the galaxy at longer wavelengths might mean that it contains more dust than expected, or show whether a feature in one band might be an artifact (not showing up in any of the other bands). We’ve also linked to the optical image from the SDSS; these dusty and distant galaxies are often too faint to show up there, but an optical detection there makes it much more likely that we already have a spectrum for the object.

WISE infrared images of the galaxy ARG0002h6v. Note how the central galaxy shows up strongly in the two bands on the left (3.4 and 4.6 microns), but is not detected in either of the bands on the right (12 and 20 microns).
Let us know if you have suggestions or questions about the new tools; we hope that they’ll continue to lead to many future discoveries with Radio Galaxy Zoo!
Announcing Galaxy Zoo’s machine-learning competition (with prize money!)
Since Galaxy Zoo began in 2007, our scientific results have relied on the classifications of our volunteers. These have always been checked (in small numbers) against expert classifications, and several papers have explored how the Galaxy Zoo data compares to results from computers. Galaxy Zoo has compared well with both expert and automated classifications, and that’s helped underscore the science that your observations have made possible.
While doing real science with the Zooniverse has always been our primary goal, we’re also looking to the future; upcoming telescopes like the SKA, LSST, and just-launched Gaia will have billions of new images and detected objects. This will simply be too large for citizen scientists to handle the full scope of data – even if literally everyone on the planet is involved.
This is where Galaxy Zoo will come in yet again. Our goal, which is shared by many groups of astronomers, is to improve the accuracy of the galaxy classifications that can be performed by computers. We’ve done some of this already (Banerji et al. 2010, Huertas-Company et al. 2011), but it’s still not good enough for much of the science we want to do. If we can make these algorithms better, future datasets for citizen science can be selected in advance; we can automatically process the bulk of the images, but still have citizen scientists play a key role in classifying at the more unusual objects. Citizen scientist results will also provide important calibration for the algorithms, and will continue to look for weird and wonderful discoveries like the Voorwerp.
With that goal in mind, we’re pleased to announce the launch of a data science competition for Galaxy Zoo. We’ve partnered with Kaggle, an online platform for predictive modeling that has a massive amount of experience in similar projects. Also working with us is Winton Capital: they’ve generously agreed to provide prize money for the winners of this competition. The first prize is $10,000 USD — we hope this will help incentivize some really great solutions!
Here’s how the competition works. On the Kaggle website, competitors will be given a large set of JPG galaxy images (taken from Galaxy Zoo 2), as well as a big text file with a few dozen variables for each image. These data are a modified version of the classifications that citizen scientists generated in GZ2 (and published in Willett et al. 2013). The goal for competitors is to come up with an algorithm that will predict what those classifications should be based only on the picture. These algorithms are submitted to Kaggle and tested against a second, private set of GZ2 images and classifications. The highest scores on the new set will win the prize money.

Galaxy Zoo’s machine learning challenge. Hosted by Kaggle and sponsored by Winton Capital.
We’re really excited about this competition. For Winton, this will help them identify promising candidates who are skilled at predictive analysis that they might be interested in hiring. For Galaxy Zoo, we’ll use the results for two major things: efficient selection of sources for upcoming citizen science projects, AND analyzing the results to see how the algorithms relate to physical properties of galaxies.
The competition is open to anyone in the world, and will run for three months, ending on March 21, 2014. Participants will need significant programming experience, and a math/astronomy background would probably help since the project relies on image analysis and machine learning. If you’re interested, check out the project at https://www.kaggle.com/c/galaxy-zoo-the-galaxy-challenge.
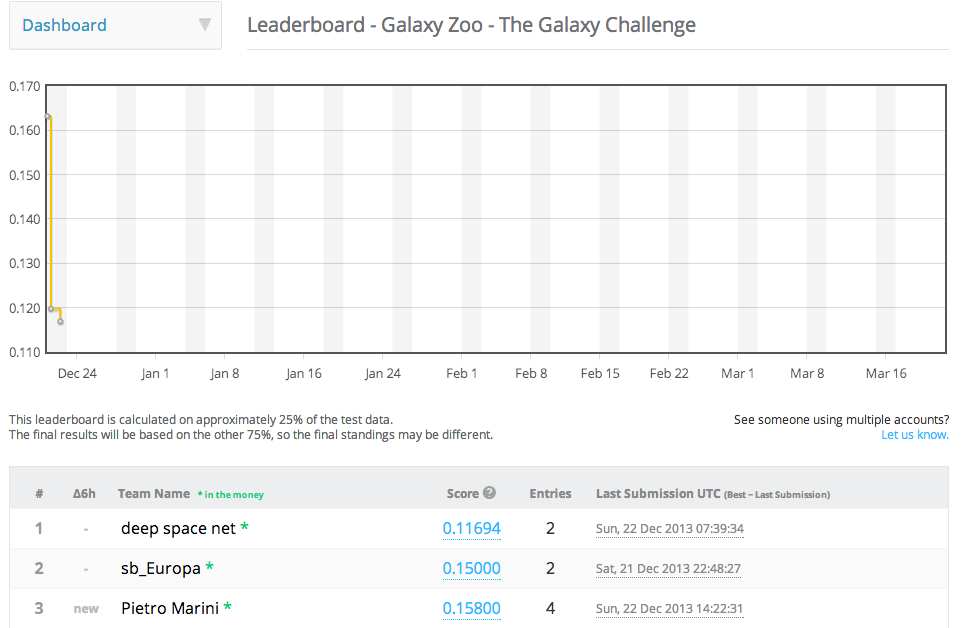
Galaxy Zoo Challenge Leaderboard, as of 22 Dec 2013.
Radio Galaxy Zoo: a close-up look at one example galaxy
We hope everyone’s been excited about the first few days of Radio Galaxy Zoo; the science and development teams certainly have been. As part of involving you, the volunteers, with the project, I wanted to take the opportunity to examine and discuss just one of the RGZ images in detail. It’s a good way to highlight what we already know about these objects, and the science that your classifications help make possible.
For an example, I’ve chosen the trusty tutorial image, which almost everyone will have seen on their first time using RGZ. We’ll be focusing on the largest components in the center (and skipping over the little one in the bottom left for now).

The tutorial image for Radio Galaxy Zoo
The data in this image comes from two separate telescopes. Let’s look at them individually.
The red and white emission in the background is the infrared image; this comes from Spitzer, an orbiting space telescope from NASA launched in 2003 (and still operating today). The data here used its IRAC camera at its shortest wavelength, which is 3.6 micrometers. As you can see, the image is filled with sources; the round, smallest objects are either stars or galaxies not big enough to be resolved by the telescope. Larger sources, where you can see an extended shape, are usually either big galaxies or star/galaxy overlaps that lie very close together in the sky.
Overlaid on top of that is the data from the radio telescope; this shows up in the faint blue and white colors, as well as the contour lines that encircle the brightest radio components. The telescope used is the Australia Telescope Compact Array (ATCA) in rural New South Wales, Australia. This data was taken as part of the ATLAS survey, which mapped two deep fields of the sky (named ELAIS S1 and CDF-S) in the radio at a wavelength of 20 cm.
So, what do we know about the central sources? From their shape, this looks like what we would call a classic “double lobe” source. There are two radio blobs of similar size, shape, and brightness; almost exactly halfway between them is a bright infrared source. Given its position, it’s a very good candidate as a host galaxy, poised to emit the opposite-facing jets seen in the radio.
This object doesn’t have much of a mention in the published astronomical literature so far. Its formal name in the NASA database is SWIRE4 J003720.35-440735.5 — the name tells us that it was detected as part of the SWIRE survey using Spitzer, and the long string of numbers can be broken up to give us its position on the sky. This is a Southern Hemisphere object, lying in the constellation Phoenix (if anyone’s curious).
The only analysis of this galaxy so far appeared in a paper published by RGZ science team member Enno Middelberg and his collaborators in 2008. They made the first detections of the radio emission from the object, and matched the radio emission to the central infrared source by using an automatic algorithm plus individual verification by the authors. They classified it as a likely AGN based on the shape of the radio lobes, inferring that this meant a jet. It’s also one of the brighter galaxies that they detected in the survey, as you can see below – brighter galaxies are to the right of the arrow. That might mean that it’s a particularly powerful galaxy, but we don’t know that for sure (for reasons I’ll get back to in a bit).
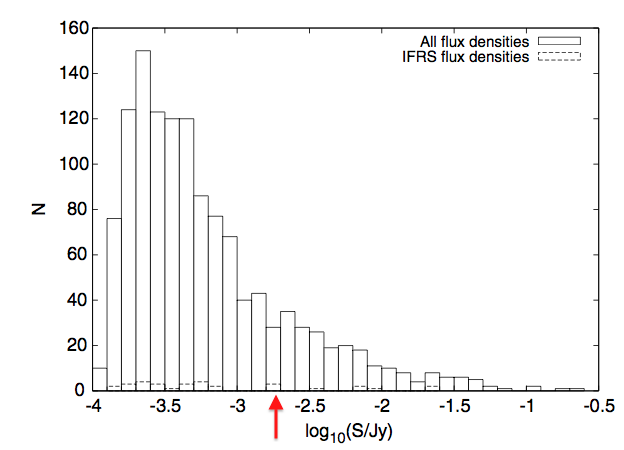
The brightnesses (measured in radio) of galaxies in ATLAS-SWIRE. From Middelberg et al. (2008).
So what we know is somewhat limited – this object has only ever been detected in the radio and near-infrared, and each of those only have two data points. The galaxy is detected at both at 3 and 4 micrometers in the infrared, but the camera didn’t detect it using any of its longer-wavelength channels. This makes it difficult to characterize the emission from the host galaxy; we need more measurements at additional wavelength to determine whether the light we see (in the non radio) is from stars, from dust, or from what we call “non-thermal processes”, driven by black holes and supernovae.
One of the biggest barriers to knowledge, though, is that the galaxy doesn’t currently have a measured distance. Distances are so, so important in astronomy – we spend a massive amount of time trying to accurately figure out how far away things are from the Earth. Knowing the distance tells us what the true brightness of the galaxy is (whether it’s a faint object nearby or a very bright one far away), what the true physical size of the radio jets are, at what age in the Universe it likely formed; a huge amount of science depends critically on this.
Usually distances to galaxies are obtained by taking a spectrum of it with a telescope and then measuring the Doppler shift (redshift) of the lines we detect, caused by the expanding Universe. The obstacle is that spectra are more difficult and more expensive to obtain than images; we can’t do all-sky surveys in the same way we can with just images. This is one reason why these cross-identifications are important; if you can help firmly identify the host galaxy, we can effectively plan future observations on the sources that need it.

{kind=link}
{kind=link}