
Scaling Galaxy Zoo with Bayesian Neural Networks
This is a technical overview of our recent paper (Walmsley 2019) aimed at astronomers. If you’d like an introduction to how machine learning improves Galaxy Zoo, check out this blog.
I’d love to be able to take every galaxy and say something about it’s morphology. The more galaxies we label, the more specific questions we can answer. When you want to know what fraction of low-mass barred spiral galaxies host AGN, suddenly it really matters that you have a lot of labelled galaxies to divide up.
But there’s a problem: humans don’t scale. Surveys keep getting bigger, but we will always have the same number of volunteers (applying order-of-magnitude astronomer math).
We’re struggling to keep pace now. When EUCLID (2022), LSST (2023) and WFIRST (2025ish) come online, we’ll start to look silly.

To keep up, Galaxy Zoo needs an automatic classifier. Other researchers have used responses that we’ve already collected from volunteers to train classifiers. The best performing of these are convolutional neural networks (CNNs) – a type of deep learning model tailored for image recognition. But CNNs have a drawback. They don’t easily handle uncertainty.
When learning, they implicitly assume that all labels are equally confident – which is definitely not the case for Galaxy Zoo (more in the section below). And when making (regression) predictions, they only give a ‘best guess’ answer with no error bars.
In our paper, we use Bayesian CNNs for morphology classification. Our Bayesian CNNs provide two key improvements:
- They account for varying uncertainty when learning from volunteer responses
- They predict full posteriors over the morphology of each galaxy
Using our Bayesian CNN, we can learn from noisy labels and make reliable predictions (with error bars) for hundreds of millions of galaxies.
How Bayesian Convolutional Neural Networks Work
There’s two key steps to creating Bayesian CNNs.
1. Predict the parameters of a probability distribution, not the label itself
Training neural networks is much like any other fitting problem: you tweak the model to match the observations. If all the labels are equally uncertain, you can just minimise the difference between your predictions and the observed values. But for Galaxy Zoo, many labels are more confident than others. If I observe that, for some galaxy, 30% of volunteers say “barred”, my confidence in that 30% massively depends on how many people replied – was it 4 or 40?
Instead, we predict the probability that a typical volunteer will say “Bar”, and minimise how surprised we should be given the total number of volunteers who replied. This way, our model understands that errors on galaxies where many volunteers replied are worse than errors on galaxies where few volunteers replied – letting it learn from every galaxy.
2. Use Dropout to Pretend to Train Many Networks
Our model now makes probabilistic predictions. But what if we had trained a different model? It would make slightly different probabilistic predictions. We need to marginalise over the possible models we might have trained. To do this, we use dropout. Dropout turns off many random neurons in our model, permuting our network into a new one each time we make predictions.
Below, you can see our Bayesian CNN in action. Each row is a galaxy (shown to the left). In the central column, our CNN makes a single probabilistic prediction (the probability that a typical volunteer would say “Bar”). We can interpret that as a posterior for the probability that k of N volunteers would say “Bar” – shown in black. On the right, we marginalise over many CNN using dropout. Each CNN posterior (grey) is different, but we can marginalise over them to get the posterior over many CNN (green) – our Bayesian prediction.

Read more about it in the paper.
Active Learning
Modern surveys will image hundreds of millions of galaxies – more than we can show to volunteers. Given that, which galaxies should we classify with volunteers, and which by our Bayesian CNN?
Ideally we would only show volunteers the images that the model would find most informative. The model should be able to ask – hey, these galaxies would be really helpful to learn from– can you label them for me please? Then the humans would label them and the model would retrain. This is active learning.
In our experiments, applying active learning reduces the number of galaxies needed to reach a given performance level by up to 35-60% (See the paper).
We can use our posteriors to work out which galaxies are most informative. Remember that we use dropout to approximate training many models (see above). We show in the paper that informative galaxies are galaxies where those models confidently disagree.
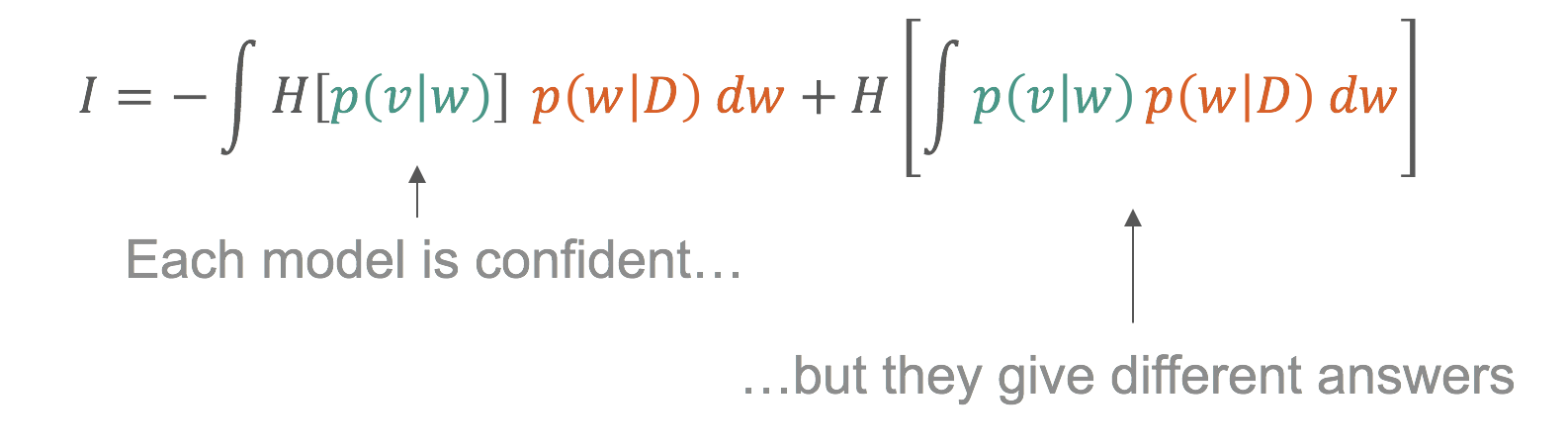
This is only possible because we think about labels probabilistically and approximate training many models.
What galaxies are informative? Exactly the galaxies you would intuitively expect.
- The model strongly prefers diverse featured galaxies over ellipticals
- For identifying bars, the model prefers galaxies which are better resolved (lower redshift)
This selection is completely automatic. Indeed, I didn’t realise the lower redshift preference until I looked at the images!
I’m excited to see what science can be done as we move from morphology catalogs of hundreds of thousands of galaxies to hundreds of millions. If you’d like to know more or you have any questions, get in touch in the comments or on Twitter (@mike_w_ai, @chrislintott, @yaringal).
Cheers,
Mike
