
Introducing Galaxy Zoo: Clump Scout II

Hi everyone,
If you’ve been following Galaxy Zoo for a while, you may remember the Galaxy Zoo: Clump Scout project. Now, Clump Scout is back, and we need your help with Galaxy Zoo: Clump Scout II!
The first Clump Scout project
Back in 2019, we asked you to help us find giant star forming clumps (or just “clumps”) in nearby galaxies. With your help, the first Clump Scout project was a resounding success. Over 14,000 volunteers took part, looking at nearly 60,000 galaxy images from the Sloan Digital Sky Survey (SDSS) and making millions of individual classifications. When the project completed, you had helped us identify clumps in more than 7,000 galaxies, giving us what was then the largest catalogue of clumpy systems in the local Universe.
What have we been doing since Clump Scout finished?
We’ve learned a lot from the results of Galaxy Zoo: Clump Scout and they provided a crucial foundation for the research that followed. By using the results to train a Deep Learning model, we were able to discover 41,445 bright clumps in 34,246 galaxies by searching over 240,000 SDSS galaxy images. This expanded clumpy galaxy sample allowed us to investigate whether clumpy galaxies are more prevalent in dense galaxy clusters or in the sparse voids between clusters.
Since then, we have continued to update our clump detection deep learning model and we have tried to fine-tune it to detect clumps in survey data from more powerful telescopes like the Subaru Telescope, and most recently the Euclid Space Telescope. These telescopes allow us to find fainter, smaller clumps in more distant galaxies and they produce sharper images that start to reveal the individual clumps’ substructure.
New images
The three images in the figure below show the same galaxy as seen by the SDSS, the Hyper Suprime-Cam (HSC) camera on the 8-metre-diametre Subaru Telescope, and the two cameras on board the Euclid Space Telescope. The galaxy is barely visible in the SDSS image and certainly doesn’t show any obvious signs of being clumpy. In the HSC image the galaxy is clearly visible and shows several clumps that appear as bright, somewhat blurry blobs lying along the galaxy’s spiral arms. The Euclid image is much sharper and shows that the individual clumps from the HSC have complex substructure.

Figure 1. Three images of the same clumpy galaxy as seen by the SDSS Survey’s Apache Point 4 metre class telescope (left), the Hyper Suprime-Cam imager on the 8-metre diameter Subaru Telescope (centre) and the VIS and NIR cameras on the Euclid Space Telescope (right).
New science
Clumps are sites of intense star formation, which can deliver energy to their surroundings via several processes, which are often described collectively as “feedback”. For example, stellar radiation, stellar winds (streams of fast-moving charged particles launched from stars’ surfaces) and supernova explosions can all inject energy into the interstellar medium in and around the clumps. These feedback processes can have profound implications for the effect of clumps on galaxies’ growth and evolution. However, the effects of feedback depend crucially on how well it transfers energy out of the clump and how long the clump survives before being disrupted by material in their host galaxy’s disk. Both factors remain poorly constrained by observations.
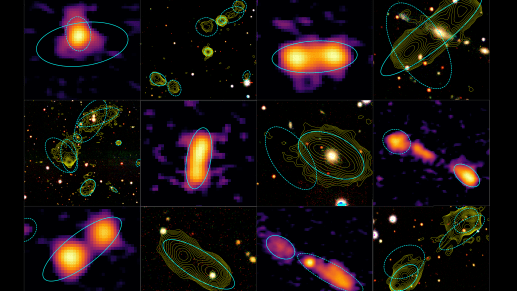
How can high resolution Euclid images help to reveal the impact of feedback from clumps? Well, the Euclid images give us the ability to observe and study the detailed substructure of clumps. This is very useful because it allows us to compare real clumps with those produced in high resolution simulations of clumpy galaxies. An example comparison is shown in the figure below. These high-resolution simulations suggest that clump substructural morphology (the distribution of sub-clump shapes and sizes) is strongly correlated with feedback-related properties of clumps, including their longevity and how much energy from their internal star formation they can impart to their surroundings.
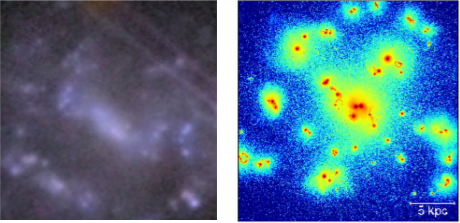
Figure 2. A clumpy galaxy observed with Euclid (left) compared to a simulated clumpy galaxy (right). With the detailed images we are now getting from Euclid, we can begin to study the substructures of clumps that we see should be there in simulations, telling us about clump properties like how long they can survive.
If clumps are resilient to disruption, then tidal forces are expected to make them migrate slowly towards the centres of their host galaxies. Feedback that is generated by the clumps’ as they migrate can regulate star formation in their host galaxies and may even drive gas and dust into the surrounding interstellar medium. Once clumps reach their host galaxy’s centres, they can dissolve and contribute to the growth of galaxy bulges.
The physical properties of simulated clumps can be directly extracted from the simulation data. If we find populations of real and simulated clumps with matching substructural morphology, then we will be able to infer that the physical properties of the real clumps are similar to the known properties of the simulated clumps.
New challenges
The new Euclid images provide new insights into the physics of clumps and clumpy galaxies but they also bring some challenges. Our clump detection model was trained using images with relatively coarse spatial resolution in which clumps normally look like blurry blobs. The complex substructure of the clumps in the Euclid images makes them more difficult for our model to identify. Our model that worked so well on low resolution images now gets confused and starts to mistake other objects, like foreground stars and background galaxies for clumps. Teaching the model to avoid these mistakes is one of the main purposes of Galaxy Zoo: Clump Scout II.
New project
Your task in Galaxy Zoo: Clump Scout II is to correct the clump labels generated by our model. You will be shown an image of a galaxy that our model thinks is clumpy with different coloured boxes, representing our model’s labels, overlaid. The figure below shows an example of the classification interface.
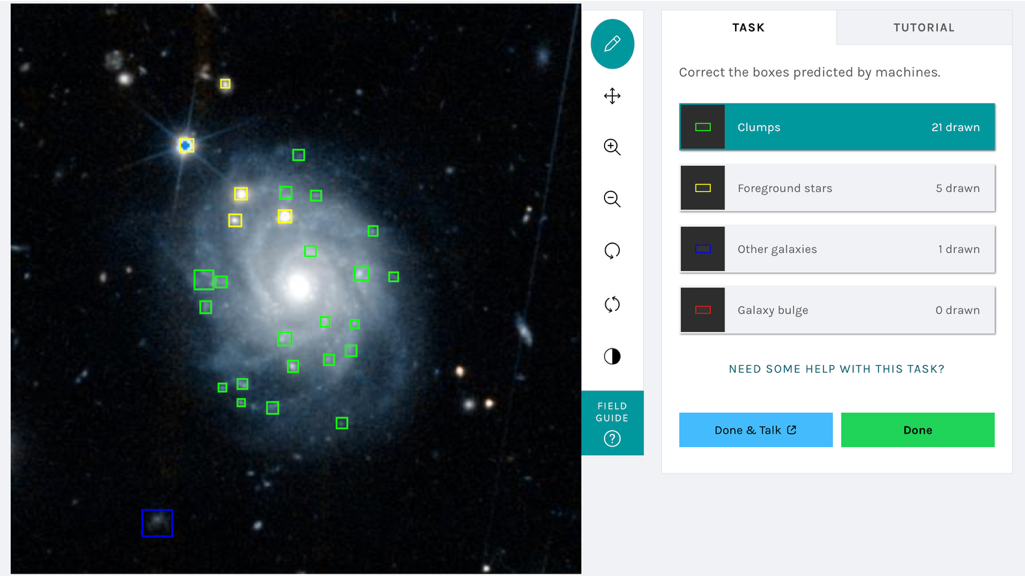
Figure 3. The Galaxy Zoo: Clump Scout II interface
The different box colours represent different types of astrophysical object – green for clumps, yellow for foreground stars, blue background galaxies and red for galaxies’ central bulges. We need you to examine all the boxes, make sure they surround real objects and check that those objects are marked with boxes of the correct colour. We also need you to mark any clumps that our model has missed. Your corrected labels will be used to incrementally retrain our model until it is able to accurately find all the clumps and contaminating clump-like objects in Euclid images.
Our finetuned model will ultimately allow us to search over 250 million Euclid galaxy images for clumps and assemble an enormous catalogue of clumps to analyse, helping to reveal the internal physical processes that drive the evolution of clumps, their host galaxies and their extragalactic surroundings.To get involved head over to Galaxy Zoo: Clump Scout II and start classifying today!
This project makes use of Q1 data from European Space Agency’s Euclid mission; learn more here: cosmos.esa.int/web/euclid/euclid-q1-data-release
Radio Galaxy Zoo: LOFAR – A short update
A lot has happened on the Radio Galaxy Zoo since we last posted an update!

First of all, you can see on the image above that we are making great progress with getting all of the big, bright sources from the LOFAR survey looked at by Zooniverse volunteers. We are approaching half a million classifications and just under 80,000 radio sources have been looked at by at least five volunteers at the time of writing. Together with the earlier efforts by members of the LOFAR team, we have covered a very wide area of the sky, around 3,000 square degrees, which is well over half of the area of the LOFAR data, and are well on the way to completing the original aims of the project. The green, orange and pink areas together show the areas of the sky we have completed.
What’s next? One of the key goals of the LOFAR Radio Galaxy Zoo has always been to provide targets for the WEAVE-LOFAR spectroscopic survey. WEAVE is a new spectroscope being commissioned on the William Herschel Telescope, which can measure 1,000 redshifts of galaxies in a single observation. WEAVE-LOFAR aims to find the redshifts of every bright LOFAR source in the survey. But the survey can’t work without knowing where the optical host galaxies are — so the input of Zooniverse volunteers in selecting these host galaxies is absolutely crucial to our success.
A complication is that WEAVE wants to look at all LOFAR sources, not just the large ones that we generally select for the Zooniverse project. As regular users will know, there are many small sources in the radio sky as well, and the optical counterparts of those can be found automatically just by matching with optical catalogues. In between there are some intermediate-sized sources, and these present the biggest problem; some of them benefit from viewing by volunteers, but there are too many of them for us to look at them all. Earlier in the year we selected 10,000 of these in a particular region of the sky that we thought would benefit from human inspection using a combination of algorithms and machine learning, and injected them into the Zooniverse project to see what volunteers made of them. The results are encouraging and have allowed us to develop a process of ‘early retirement’ for sources that turn out not to be interesting (i.e. no clicks are made during classification). Our next priority is to select this type of source, informed by the first set of results, over a larger area of the sky in order to get the full set of inputs for the first year of WEAVE. You’ll see these sources entering the Zooniverse project over the coming weeks.
Radio Galaxy Zoo: LOFAR – The First Classification Results
Presenting some results from the first two weeks of the Radio Galaxy Zoo: LOFAR project.
Hi everyone! We are extremely excited to see how popular the Radio Galaxy Zoo: LOFAR project is. Since we launched two weeks ago we’ve already had over 234,000 classifications! In this brief blogpost we’d like to give an overview about the classification statistics and how the project is coming along. The in-depth scientific results will follow later, after more careful analysis.
Some General Statistics

In the graph above, you can see the number of classifications per hour. The graph starts at the launch date of the project (25/02) as you can see from the smaller first peak, we started at about 500 classifications an hour. Things really start taking off rapidly around the morning of the next day, as the European press released their articles about the Radio Galaxy Zoo: LOFAR, peaking at 3000 classifications an hour! Afterwards, we see the generally expected day and night trends, following European time, thus indicating most volunteers are European.

The figure above shows the number of classifications grouped per language setting. As is very clear, English is the dominant one, almost 80% of the classifications are made through the English version of the website. However, French is also a pretty popular langauge setting. This is just a proxy for the distribution of the countries however. It is a bit of a skewed view since there are probably many users that prefer to view the website in English, even when that is not their native language. This is the most likely explanation for the low number of classifications using Dutch language settings. You would expect a lot of classifications with the Dutch settings as the LOFAR telescope itself is located primarily in the Netherlands and therefore has gotten more attention from the Dutch press.

We’d also like to show the distribution of the number of classifications per user. When we zoom out (the right figure) we can see that there are a few users competing hard for the most classifications, right now there is a clear number one at more than 6,000 classifications already, which is amazing.
Interesting Sources
As of the time of writing this blogpost, we have already found a ton of interesting sources. Many very nice examples of classical double lobes, but also many complex cases and beautiful starforming galaxies have been identified already. As the project has just started, we have not had time to analyze the sources in detail yet, but stay tuned for updates on this!

Common Pitfalls
An interesting thing we noticed was that many people found ‘explosions’ in the Radio Galaxy Zoo: LOFAR, like the one in the image below. Unfortunately, these radial spokes are not an explosion but just imaging artefacts from where our calibration fails, which usually happens around very bright sources. If you see something like this, please click on “Artefact” at the final “Additional information” task.

Additionally, (real) diffuse emission is often mistaken for artefacts, but emission that is not mapping any compact structure is not necessarily an artefact, like the image below:

On the other hand, the small islands of emission in the image below are actually artefacts. Watch out!

Finally, some double lobes were also identified as blends, but this is likely just by volunteers that are still getting the hang of it. See the image below for two example cases that were incorrectly identified as a blend (three and four out of five times respectively). However, these are both just classic double-lobed radio galaxies.

Of course, this is just nitpicking on the cases that are going wrong, but most of the cases seem to be going well. Many real blended sources have also been identified, such as the examples below! So the option “Blend” should be picked when two distinct radio sources are under the solid ellipse.

How much sky have you covered so far?
The progress of the first two weeks of the Radio Galaxy Zoo: LOFAR has been amazing. In terms of sky area, the citizen scientists have already seen a quite a big chunk of the northern sky that we want to cover. The image below shows the sky area that we are currently investigating in light blue (called DR2, for data release 2). The purple and orange dots show the fields that the LOFAR team has done internally for the first data release (DR1) and for a small part of the second data release, respectively. The green dots show the fields that the public Radio Galaxy Zoo: LOFAR project has completed thus far.
You can see that in just two weeks we’ve already more than doubled the amount of area that took months for scientists to look at during the first data release of the LOFAR survey! If we keep up the current pace, we will be finished in no time.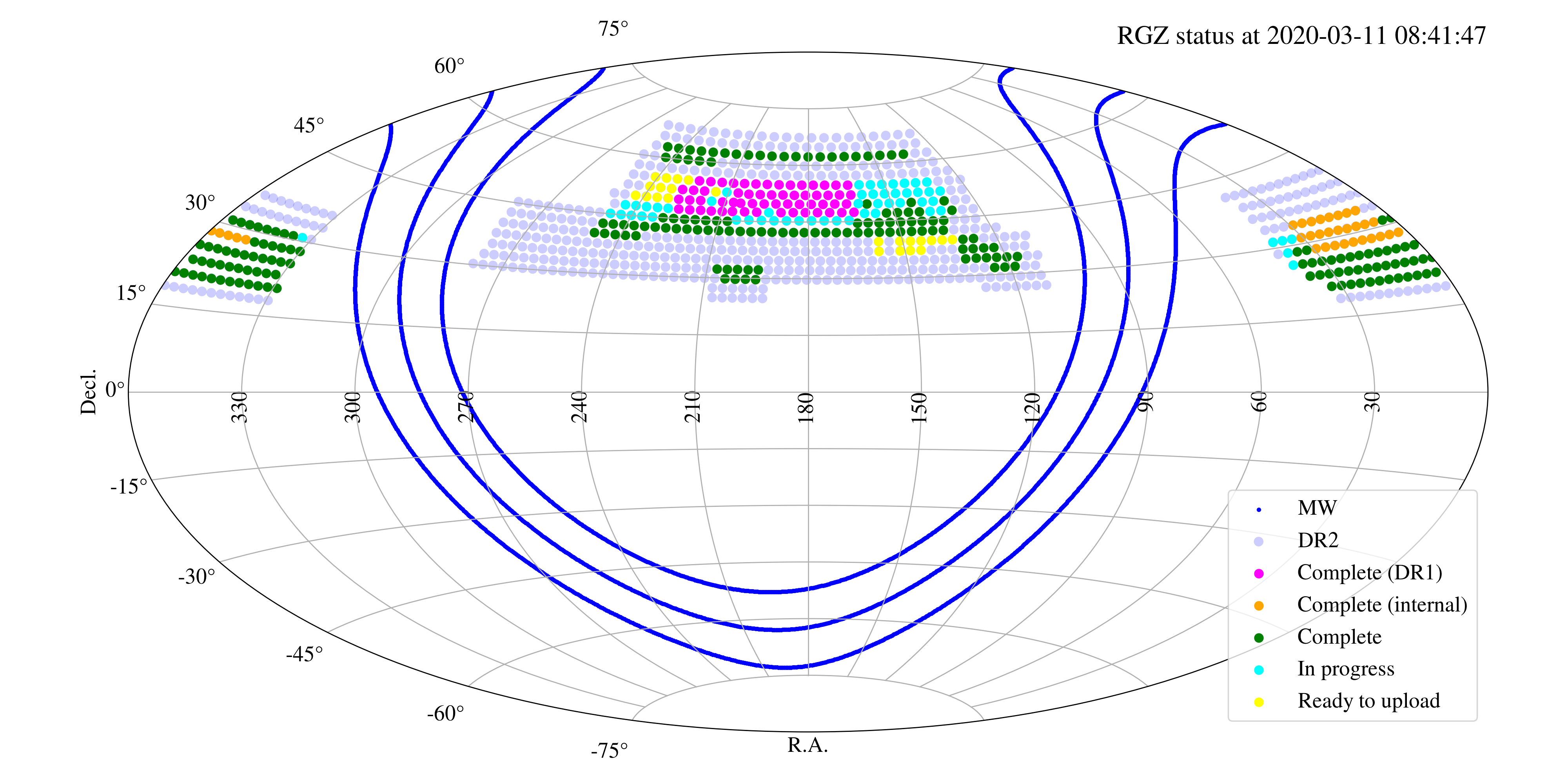
As the project continues, we plan to give you more updates on the data reduction process, so stay tuned!
Introducing Galaxy Zoo: Clump Scout, a new citizen science project
Hi, I’m Nico. I’m a 2nd year PhD student at the University of Minnesota studying galaxies. In particular, I use statistics and machine learning to extract useful information from ever-growing galaxy catalogs astronomers have assembled over the last few decades.
Today, I get to announce a completely new project by the Galaxy Zoo team!
Galaxy Zoo: Clump Scout is a citizen science project that will take a closer look at galaxies that were classified in the Galaxy Zoo 2 project. In that project, many of you answered questions for us about their shape, structure and properties. This time we’ll be examining them in an even more detailed way.
We are searching galaxies to find “giant star-forming clumps”, or just “clumps” for short. This is what astronomers call small regions within galaxies where stars are being born at a faster-than-usual rate. They are called “giant” in comparison to any individual star or group of stars — clumps can contain millions or even billions of stars — but they’re usually quite tiny compared to the galaxy containing them. The new stars formed in clumps are brighter and more densely packed than those in the rest of the galaxy, so when photographed, clumps tend to look like small glowing areas that stand out from the background. We call any galaxy with a region like this a “clumpy galaxy”. (And yes, we promise that the word “clump” will start to sound less silly with time.)

Figure 1: Some examples of clumpy galaxies that will appear in Galaxy Zoo: Clump Scout. In these images, clumps look like small, blue spots on the galaxies. Some of the clumps in these images are bright and obvious, while others take a bit more care to spot. All photos were taken by the Sloan Digital Sky Survey.
In the Clump Scout project, we are asking volunteers to look at galaxies and click on all the clumps they can see. This is a straightforward task, but many clumps require a keen eye to pick out. Once complete, your clicks will tell us where clumps are found in thousands of galaxies in the local universe. This will be one of the first large-scale studies of clumps in local galaxies, and I’m very excited to see what we find!

Figure 2: A classification from Galaxy Zoo: Clump Scout. Here, a red icon marks the central bulge of the galaxy, while six green icons mark clumps.
Why study clumps?
Clumpy galaxies have been a bit of a mystery for scientists for a while now. Astronomers have known of their existence for decades, but discussion about them really began in the late 1990s when the Hubble telescope began to capture images of very distant galaxies. Because light takes time to travel, we saw these distant galaxies as they existed billions of years ago, at a time when the universe was still young. As we studied Hubble’s images, we started to notice differences between the early galaxies and galaxies that exist today. One such difference: In the past, nearly ALL galaxies were clumpy! Discovering this was surprising, because most galaxies in the present-day universe do not have any clumps.
It’s not yet clear how clumps were formed, why they are vanishing over time, or exactly what fraction of galaxies contain clumps. What we do know is that clumps seem to change through time alongside the galaxies that contain them. As we come to better understand clumps, we hope to better understand the role they play in the growth and evolution of their host galaxies.
Why citizen science?
Part of the reason why Clump Scout is so exciting is that this is the first time human eyes will examine so many clumpy galaxies first-hand. Thanks to the help of citizen scientists, the Clump Scout project will be able to examine over fifty thousand galaxies. To speed things along, we have already filtered these galaxies with volunteer classifications from the Galaxy Zoo 2 project and picked out the subjects that volunteers marked as having “features”. By doing this, we eliminated nearly 200,000 galaxies that are very unlikely to contain clumps, leaving only more promising subjects.
We will also be testing to see which types of clumps volunteers are able to spot. There are certain clumps that are too faint to be seen no matter where they are, while others reside in bright regions of the galaxy which drown out their signal. To quantify these effects, we have taken some galaxy images and added a few of our own, simulated clumps on top. By marking these simulated clumps, you will provide us with a wealth of information about what types of clumps we can reasonably expect to find. For example, if volunteers mark a particular simulated clump 100% of the time, it is a good sign to us that a real clump like it would be found as well. On the other hand, if no volunteers see a simulated clump, we know that similar clumps are very unlikely to be found by this project.

Figure 3: An example galaxy before and after simulated clumps were added to it. On the right, a total of 5 extra clumps have been added, but several are too faint to be seen in this image.
Why can’t computers do this?
As with many citizen science tasks, identifying clumps is fairly easy for humans to do, but difficult for computers. There have actually been a few algorithms so far that could identify clumps with some success, but it’s an exceptionally difficult task to get right. Computers must be trained to ignore all the extraneous details in an image — including background galaxies, stars in our own galaxy, and galactic features like the central bulge — to find clumps among the competing signals. Luckily, this sort of task is second nature for human beings.
Computers also tend to be very bad at finding objects they aren’t specifically instructed to find. We hope that as this project proceeds, you’ll be able to help point out some exceptionally strange clumps, or even some features we do not expect at all. It was the keen eyes of Galaxy Zoo volunteers that led to the discovery of Green Peas, a class of galaxy that is still being researched today.
This project has been in the works for the last few years, and we’re very excited to see it launch. If you’d like to try it out, you can take part here.
Spectracular Performance!
During the past 10 years Galaxy Zoo volunteers have done amazing work helping to classify the visual appearance (or “morphology”) of distant galaxies, which has enabled fantastic science that wouldn’t have been possible without your help.
Morphology alone encodes a wealth information about the physical processes that drive the formation and ongoing evolution of galaxies, but we can learn even more if we analyze the spectrum of light they emit.
For the 100th Zooniverse project we designed the Galaxy Nurseries project to get your help analyzing galaxy spectra obtained by the Hubble Space Telescope (you can find many more details about Galaxy Nurseries on the main project research pages and this previous blog post).
If you participated in Galaxy Nurseries, then the data you analyzed were generated using a technique called slitless spectroscopy. In slitless spectroscopy all the light entering the HST aperture is dispersed (or split) into its separate frequencies before being projected directly into the telescope’s camera. Figure 1 illustrates a typically confusing result!

Figure 1: Example of data obtained by the Hubble Space Telescope using slitless spectroscopy.
Each bright horizontal streak in the image shown in Figure 1 is actually the spectrum of a different galaxy or star. Analyzing these data can be very tricky, especially when nearby galaxy spectra overlap and cross-contaminate each other. Automatic algorithms really struggle to reliably distinguish between spectral contamination and scientifically interesting features that are present in the spectra. This means that scientists almost aways need to visually inspect any features that are automatically detected in order to ensure that they are really there!
In Galaxy Nurseries, we asked volunteers to help with this verification process. We asked you to double-check over 27,000 automatically detected emission lines in galaxy spectra obtained by the WISP galaxy survey, labelling them as either real or fake. Even for professional astronomers and experienced Galaxy Zoo volunteers, verifying the presence of emission lines in slitless spectroscopic data can be very difficult. To help you discriminate between real and fake emission lines we showed you three different views of the data. Figure 2 shows an example of one of the Galaxy Nurseries subject images.

Figure 2: A Galaxy Nurseries subject showing a real emission line. The different panels show A) a 1-dimensional representation of the spectrum with the potential emission line marked ; B) a 2-dimensional “cutout” from the full slitless spectroscopic image, with the potential emission line and the expected extent of the galaxy spectrum marked; C) a direct image of the galaxy for which the spectrum was generated.
As well as the 1 dimensional spectrum shown in Figure 2 (Panel A), we also showed a “cutout” from the full slitless spectroscopic image, which isolated the target spectrum (Panel B), and a direct image of the galaxy that produced the spectrum (Panel C). The cutout in Panel B can be really useful for identifying contamination from adjacent spectra. For example, something that looks like a feature in the target spectrum might actually originate in an adjacent spectrum and would therefore appear slightly vertically off-centre in the 2-dimensional image.
Why is the direct image useful for spectroscopic analysis? Well, emission lines often appear like very slightly blurred images of the target galaxy at a specific position in the slitless spectrum. Look again at the emission line and the direct image in Figure 2. Can you see the similarity? If the shape of the automatically detected line feature in the slitless spectroscopic image doesn’t match the shape of the galaxy in the direct image, then this can indicate that the feature is just contamination masquerading as an emission line.
The response to Galaxy Nurseries was fantastic! Following its launch the project was completed in only 40 days, gathering 414,360 classifications (that’s 15 classifications per emission line) from 3003 volunteers. Huge thanks for everyones’ help! The results of the project were published in a Research Note, and the rest of this post summarizes what we learned.
Using the labels assigned to each potential emission line by galaxy zoo volunteers we computed the fraction of volunteers who classified the line and thought it was real (hereafter freal). We wanted to compare the responses of the Galaxy Zoo volunteers with those of professional astronomers from the WISP survey team (WST). To do this, we divided the potential emission lines into two sets. The verified set contained emission lines that the WST thought were real and the vetoed set contained emission lines that the WST thought were fake. We assumed that the WST assessments were correct in the vast majority of cases, but this might not be completely accurate. Even professional astronomers make mistakes!
Figure 3 shows the distributions of freal for the two sets of emission lines. The great news is that for the vast majority of lines that the WST thought were fake, over half of the volunteers agreed with them (i.e. freal < 0.5). Similarly for most of the WST-verified set of line, the majority volunteers also labeled them as real. These results show us that Zooniverse and Galaxy Zoo volunteers are very capable when it comes to separating real emission lines from the fakes.
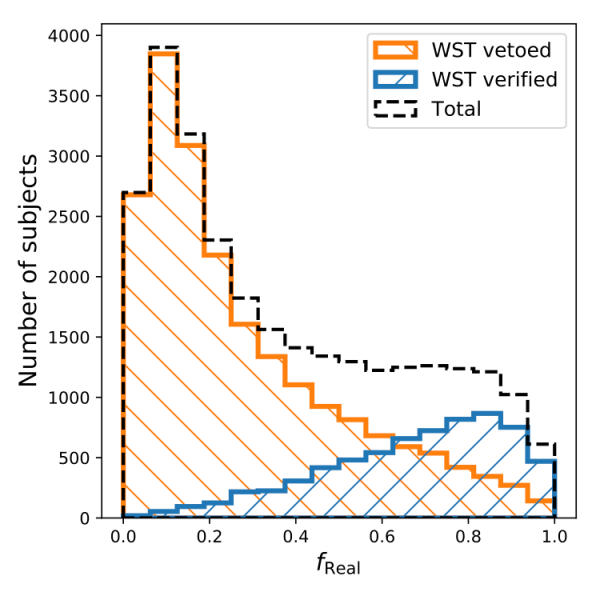
Figure 3: The distributions of freal for sets of emission lines that were verified (blue) or vetoed (orange) by the WISP survey team.
What can we say about the lines for which the volunteers and the WST disagreed? Is there something about them that makes them particularly hard to classify? Well, it turns out that the answer is “yes”!
We computed two statistical metrics to quantify the level of agreement between the Zooniverse volunteers and the WST for a particular sample of the emission lines that were classified.
- The sample purity is defined as the ratio between the number of true positives (for which both the volunteers and the WST believe the the line is real) and the combined number of true positives and false positives (for which a feature labeled as fake by the WST was labeled as real by the volunteers). The purity tells us the fraction of lines in the sample that were labeled real by the volunteers that were also labeled as real by the WST. If volunteers don’t mislabel any fake lines as real then purity is 1.
- The sample completeness is the ratio between the number of true positives and combined number of true positives and true negatives (for which the WST labeled the line as real, but the volunteer consensus was that the line was fake). The completeness tells us the fraction of lines in the sample that were labeled as real by the WST that were also labeled as real by the volunteers. If volunteers spot all the real lines identified by the WST then the completeness is 1.
Figure 4 plots purity and completeness as a function of freal and the emission line signal-to-noise ratio (S/N). Lines with higher S/N stand out more relative to the noise in the spectrum and should be easier to analyze for volunteers and the WST alike. Examining Figure 4 reveals that for subsets of candidate lines having freal less than a particular threshold value (shown on the horizontal axis), the completeness values are higher for higher S/N. This indicates that spotting real lines is much easier when the features being examined are bright, which makes intuitive sense. On the other hand, higher purities can be achieved for similar threshold values of freal as the S/N value decreases, which indicates that volunteers are reluctant to label faint lines as real. At low S/N, sample purities as high as 0.8 can be achieved when only 50% of volunteers agreed that the corresponding emission lines were real. At higher S/N, volunteers become more confident, but also seem slightly more likely to identify noise and contaminants as real lines. This is probably a reflection of just how difficult the line identification task really is. Nonetheless, samples that are 70% pure can be selected by requiring a marginal majority of votes for real ( freal value of at least 0.6), which is pretty impressive!
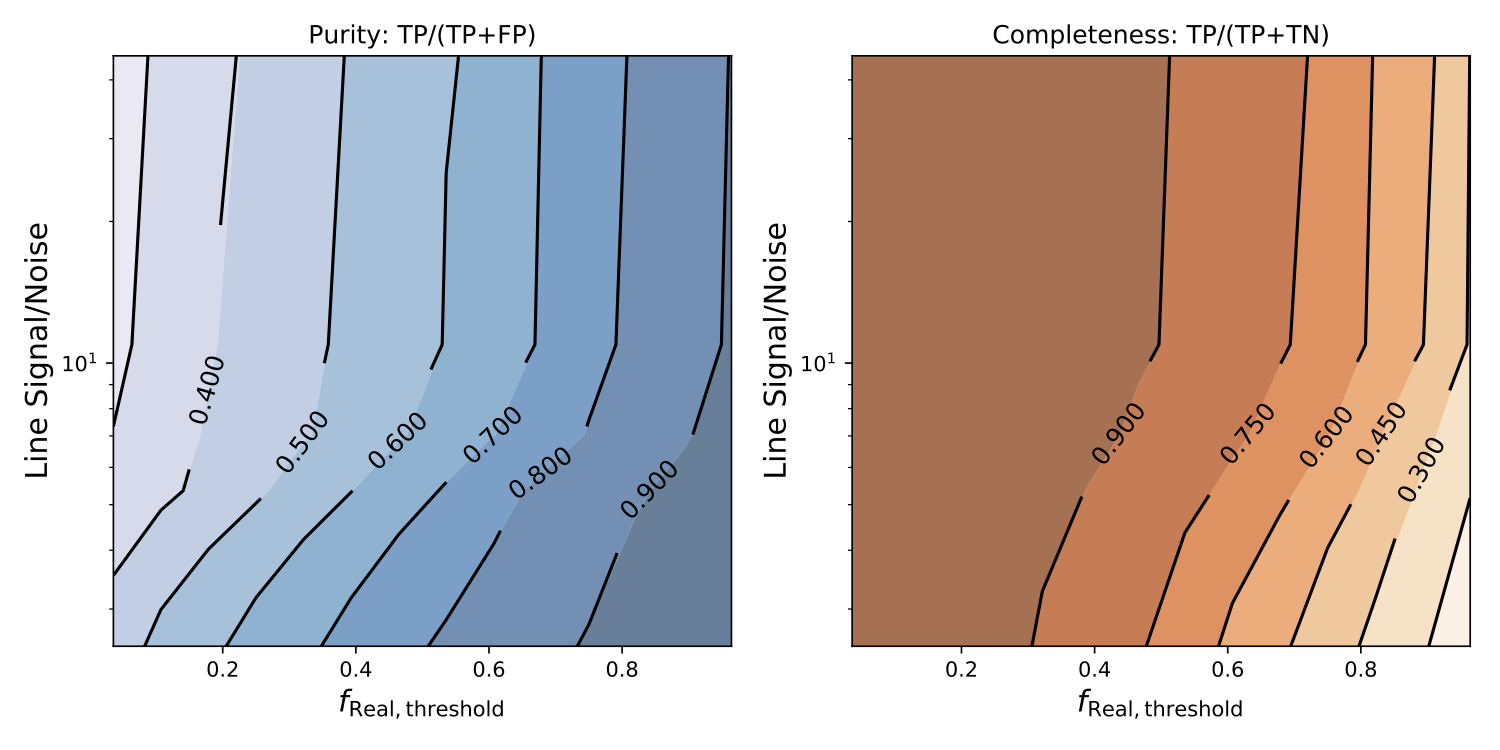
Figure 4: Sample purity (left) and completeness (right) plotted as a function of minimum freal value for any potential line in the sample, and that line’s signal-to-noise ratio.
We can use the plots in Figure 4 to select samples that have desirable properties for scientific analysis. For example, if we want to be sure that we include 75% of all the real lines but we don’t mind a few fakes sneaking in, then we could choose freal = 0.5 which would give a completeness larger than 0.75 for all S/N values. However, if we choose freal = 0.5, then the purity of our sample could be as low as 0.6 for high S/N, with about 40% of accepted lines being fake in reality.
The ability to extract very complete but impure emission line samples can be very useful. By selecting a sample that removes a sizable fraction of fakes from the automatically detected candidates, the number of potential lines that the WST need to visually inspect is dramatically reduced. It took the WST almost 5 months before each line in Galaxy Nurseries could be inspected by just two independent astronomers. By providing 15 independent classifications for each line, Zooniverse volunteers did the 8 times as much work in just 40 days! In the future, large-scale slitless spectroscopic surveys will be performed by new space telescopes like Euclid and WFIRST. These surveys will measure millions of spectra containing many millions of potential emission lines and individual science teams will simply not be able to visually inspect all of these lines. Eventually, deep learning algorithms may be able to succeed where current automatic algorithms fail. In the meantime, it is only with the help of Zooniverse and Galaxy Zoo volunteers that scientists will be able to exploit more than the tiniest fraction of the fantastic data that will soon arrive.
Classifying Galaxies from Another Universe!

We’re excited to announce the publication of another scientific study. that wouldn’t have been possible without the hard work of the Galaxy Zoo volunteers. The paper:
“Galaxy Zoo: Morphological classification of galaxy images from the Illustris simulation”
is the first Galaxy Zoo publication that examines visual morphological classifications of computer-generated galaxy images. The images were produced in collaboration with the international team of scientists who implemented and analyzed the highly sophisticated Illustris cosmological simulation (you can find many more details about Illustris on the main Illustris project website and about the Galaxy Zoo: Illustris project in this previous blog post). Illustris is designed to accurately model the evolution of our Universe from a time shortly after its birth until the present day. In the process, simulated particles of dark matter, gas, and stars aggregate and condense to form galaxy clusters that contain seemingly realistic galaxies. In our paper we wanted to test the realism of those simulated galaxies by inviting Galaxy Zoo volunteers to evaluate their morphological appearance. We wanted to know whether Illustris galaxies look like real galaxies.
But where to start looking? Well, if you’ve ever classified a galaxy on Galaxy Zoo then you must have answered a question worded something like:
Is the galaxy simply smooth and rounded, or does it have features?
This question represents one of the simplest ways to distinguish between different groups of galaxies, but its answer can reveal a lot of information about a galaxy’s history, as well as its current activity. Visible features and substructure like discs, spiral arms and bars in galaxy images often indicate sites of ongoing star formation and can provide evidence for complex dynamical processes within a galaxy. On the other hand, apparently featureless galaxies may have formed in dense environments where galaxy-galaxy interactions are more common and might act to destroy features or even prevent them from forming in the first place.
In our paper, we compared the prevalence of visible features in galaxy images that were produced using Illustris against an equivalent sample of real galaxy images that were derived from Sloan Digital Sky Survey (SDSS) observations. Some of the differences we found were surprising but quite illuminating!
Each image in Galaxy Zoo is classified by about forty volunteers and their votes for each question are aggregated to obtain a consensus. The level of agreement between volunteers can be quantified using the vote fraction for a particular response. For a particular image and question the vote fraction for a possible response is just the number of volunteers who voted for that response, divided by the total number of votes cast for that question, for that image. A concrete example that applies here is the “featured” vote fraction: the number of volunteers who classified a galaxy image as exhibiting visible features divided by the total number of votes cast for the simple question that was quoted above. Vote fractions close to zero indicate that most volunteers thought the galaxy was smooth and rounded, while vote fractions around one imply almost unanimous consensus that a galaxy has visible features.
The filled green bars in Figure 1 illustrate the distribution of this “featured” vote fraction for real galaxy images. The distribution is dominated by a peak close to zero, which means that most volunteers thought that most galaxies looked smooth and featureless. There is also a smaller peak close to one, corresponding to a population of obviously featured galaxies. In contrast, the blue line shows the “featured” vote fraction for Illustris galaxy images. The bulk of the distribution is now peaked around 0.6, which means that Illustris galaxies were generally perceived to be predominantly featured. However, there are very few Illustris galaxies that were unanimously labeled as exhibiting visible features and a substantial population of visibly smooth galaxies is also present. Overall, the Illustris galaxy images seem more feature rich, but perhaps slightly more ambiguous than their SDSS counterparts.
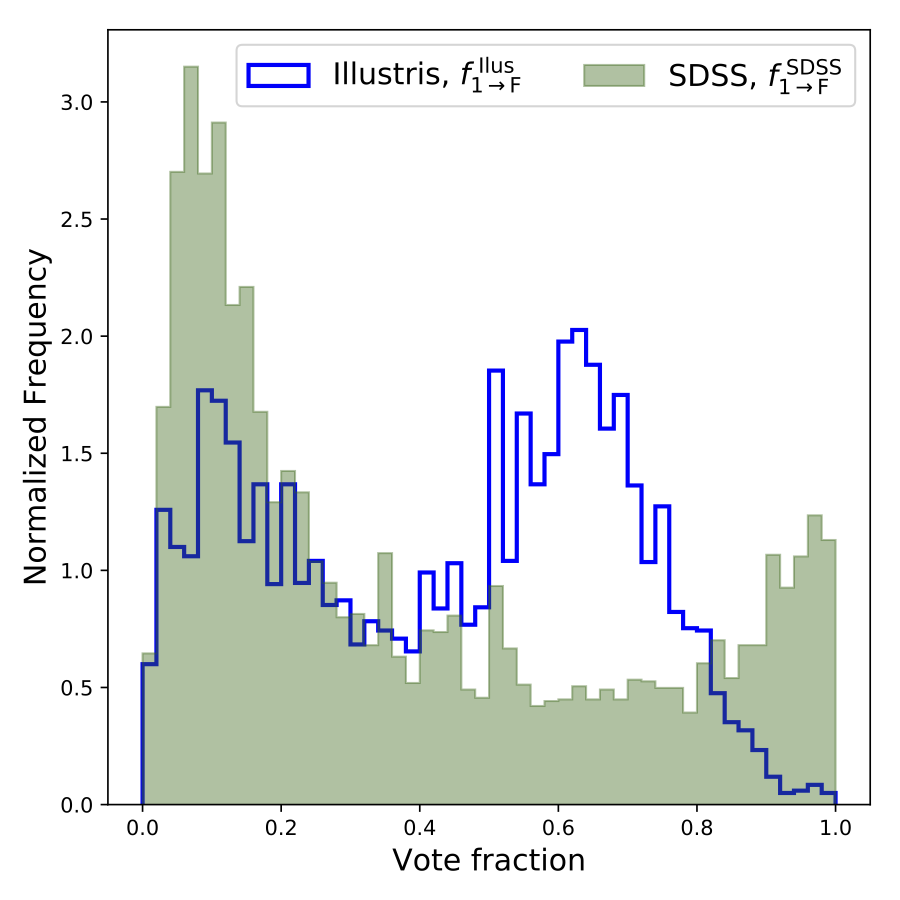
Figure 1: The distributions of the “featured” vote fraction for real (SDSS; Green, filled bars) and simulated (Illustris; Blue, hollow bars) galaxy images. There is an obvious mismatch between the distributions for the simulated and real galaxy images.
To try to understand the origin of the mismatch between Illustris galaxies and those in the real Universe, we separated both of the image samples into three sub-groups based on the total mass of the stars that the galaxies contain (more succinctly described as their “stellar mass”). Each of the panels in Figure 2 can be interpreted in the same way as Figure 1, except that they correspond only to the galaxies for each of the three stellar mass sub-groups. The two panels to the left are for galaxies with stellar masses less than the mass of 1000 billion suns. They look remarkably similar to Figure 1 with the SDSS and Illustris distributions matching very poorly. However, the situation changes markedly in the right-hand panel. For these extremely massive galaxies, it appears that the Illustris simulation reproduces the observed proportion of visibly featured galaxies much better, although the population of unambiguously featured galaxies is still absent.
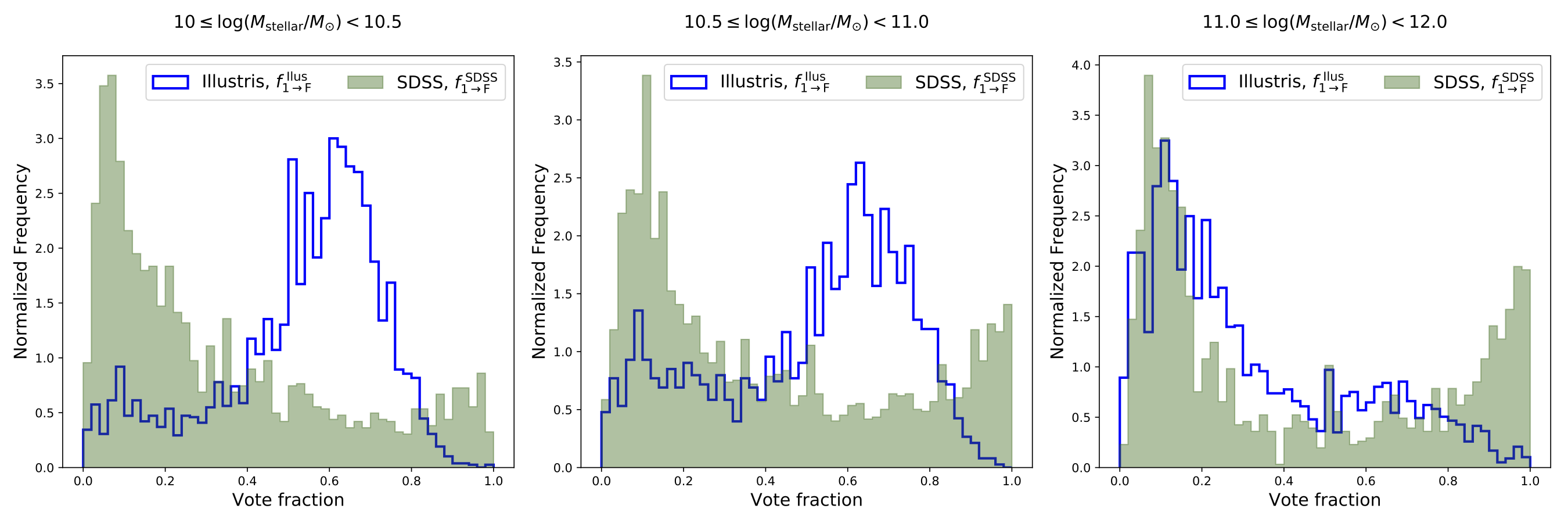
Figure 2: The distributions of the “featured” vote fraction for real (SDSS; Green, filled bars) and simulated (Illustris; Blue, hollow bars) galaxy images. The distributions are shown for sub-groups of galaxies that are subdivided according to stellar mass. The distributions for the most massive galaxies, with stellar masses greater than the mass of 1000 billion suns, are shown in the right-hand panel. It is only for these very massive galaxies that the vote fraction distributions for simulated and real galaxies begin to look similar.
The change in behavior with stellar-mass that we have identified might simply be an artifact of the finite resolution at which Illustris is able to simulate the Universe. Computational power is limited, so Illustris cannot accurately model the positions, interactions and evolution of every star in its simulation volume (and of course tracking individual gas atoms or dark matter particles is completely impossible!). Instead, Illustris models large groups of stars, and large accumulations of gas and dark matter as single “particles” and models the way that they interact with each other. The features that volunteers perceive in Illustris galaxy images manifest substructures formed by groups of many such particles. Simulated galaxies with larger stellar masses contain more stellar particles that enable the simulation to model finer structural details which may be necessary to emulate the appearance of real galaxies.
Studies involving automatic morphological classification of Illustris galaxy images (e.g. Bottrell et al 2017, Snyder et al 2015) have also identified a marked divergence with galaxies in the real Universe below the same 1000 billion solar mass limit that we have found. Confirmation that the visual appearance of galaxies also changes perceptibly complements a growing body of knowledge on this subject.
Dust is another constituent of galaxies that can substantially modify their appearance by absorbing bluer light that typically indicates star formation and re-emitting it at redder wavelengths. This dust reddening effect is not accounted for by the Illustris simulations and could obscure the visibility of features that are actually present in real galaxies. This means that Illustris might be modeling real galaxies better than it seems, and coupling of a dust reddening model to the simulation output might improve the correspondence between the mismatched vote fraction distributions at lower stellar masses.
As is often the case in scientific research, an unanticipated result has provided valuable insight. The results from Galaxy Zoo: Illustris will help cosmologists to improve their models as they develop the next generation of large-scale simulations of our Universe. The results also underline the ongoing potential utility for visual morphological classification of simulated galaxies. The most recent cosmological simulations, including a next-generation Illustris Simulation, address many of the shortcomings that this and other studies have revealed. Comparing their outputs with SDSS galaxy images, as well as observational data produced by other surveys, will undoubtedly yield more insights into the processes that govern the formation and evolution of galaxies. Watch this space!
A preprint of the new paper, which has been accepted by the Astrophysical Journal, can be downloaded from the arXiv.
