
Radio Galaxy Zoo: what radio lobe shapes tell us about the mutual impact of jets and intergalactic gas
The following blogpost is from Stas Shabala about the Radio Galaxy Zoo paper led by his student, Payton Rodman, exploring the origin of asymmetries observed in a sample of Radio Galaxy Zoo radio galaxies.
***********
Another Radio Galaxy Zoo paper has just been accepted for publication. “Radio Galaxy Zoo: Observational evidence for environment as the cause of radio source asymmetry” will shortly appear in Monthly Notices of the Royal Astronomical Society, and is already available on the preprint server (https://arxiv.org/abs/1811.03726). This paper, led by University of Tasmania undergraduate student Payton Rodman, looks at the properties of lobes in powerful radio galaxies. These lobes are inflated by a pair of jets, emerging in opposite directions from the accretion disk of the black hole at the centre of their host galaxy. Astronomers have known for a while that how big, bright or wide the radio lobes are depends on the properties of the intergalactic gas into which these lobes expand. Small, slow-growing lobes are usually found in galaxy clusters, while their large, rapidly expanding cousins tend to stay away from such dense environments. Radio lobes move about and heat intergalactic gas, and in this way they are thought to be responsible for regulating the formation of stars (by staving off the gravitational collapse of cold gas) in massive galaxies over the last eight billion years. Because of this, understanding how jets and lobes interact with their surroundings is important for understanding the history of the Universe. What complicates matters is that the mechanisms responsible for feeding the black hole and generating jets are also different in these two environments. So does nature or nurture determine what the lobes look like?

Still snapshot of hydrodynamic simulation of asymmetrical radio jets by Patrick Yates from the University of Tasmania. Check out the movie clip here
We decided to use the fact that all radio galaxies start out with two intrinsically identical jets propagating in opposite directions. If the two resultant lobes look different, this could only be due to the interaction with the surrounding gas – in other words, nurture. To test the nurture hypothesis, we used the first tranche of Radio Galaxy Zoo classifications. We selected all sources classified by citizen scientists to contain two clear radio lobes, and subjected this sample to a number of rigorous cuts on brightness, shape, redshift, and availability of environment information. Hot intergalactic gas is usually traced by X-ray observations, but these are unavailable for the majority of the sample. Instead, we used the clustering of optical galaxies from the Sloan Digital Sky Survey, which should be a good proxy for the underlying gas distribution. Then, for each radio galaxy, we compared the properties of the two radio lobes to how many galaxies were found near each of the lobes. We found a clear anti-correlation between the length of the radio lobe, and the number of nearby galaxies – in other words, shorter lobes have more galaxies surrounding them. These results were in excellent agreement with quantitative predictions from models (such as this hydrodynamic simulation made on the University of Tasmania’s supercomputer by PhD student Patrick Yates), which show that it is more difficult for lobes to expand into dense environments. The relationship between the luminosity of the lobes and galaxy clustering was much less clear, again consistent with models which predict a highly non-linear luminosity evolution as the lobes grow.
The excellent agreement between models and observations suggests that it is nurture, not nature, which determines lobe properties. It also opens up a new way of studying radio galaxy environments: though sensitive observations of optical galaxy clustering. With help from Zooites, we hope to expand this work to a much larger Radio Galaxy Zoo sample, which would allow us to probe the finer aspects of jet – environment interaction. Further afield, the ongoing GAMA Legacy ATCA Southern Survey (GLASS) project on the Australia Telescope Compact Array, as well as the Australian Square Kilometre Array Pathfinder EMU survey, will use this method to study the physics of black hole jets and the impact they have on their surroundings in a younger Universe.
Radio Galaxy Zoo’s ClaRAN
On the 31 October 2018, Radio Galaxy Zoo published its first end-to-end machine learning system for “Classifying Radio sources Automatically using Neural networks” (ClaRAN). This paper is led by ClaRAN’s developer, Chen Wu, a data scientist at the International Centre for Radio Astronomy Research at the University of Western Australia (ICRAR/UWA), who repurposed the FAST-rCNN algorithm (used by Microsoft and Facebook) to classify radio galaxies. ClaRAN was trained on radio galaxies classified by Radio Galaxy Zoo and so recognises some of the most common radio morphologies that have been classified.
The purpose of ClaRAN is to reduce the number of radio sources that require human visual classification so that future Radio Galaxy Zoo projects will have fewer “boring” sources, thereby increasing the chances of real discoveries by citizen scientists. ClaRAN (and its future cousins) are crucial for future surveys such as the EMU survey which is expected to detect ~70 million radio sources (using the Australian Square Kilometre Array Pathfinder telescope). While Radio Galaxy Zoo has made visual source classifications much more efficient, we will still need to reduce the total survey sample size to a sample for visual inspection that is less than 1% of the 70 million sources.
How does ClaRAN work? ClaRAN inspects both the radio and coordinate-matched infrared overlay in the same fashion as RGZ Zooites, and then determines the radio source component associations in a similar fashion to the RGZ Data Release 1 (DR1) catalogue. As ClaRAN is still in its prototype stage (–analogous to the capabilities of a toddler), it only understands 3 main classes of radio morphologies — sources which have 1-, 2- or 3- separate radio components. ClaRAN was trained to understand these three different radio morphologies through seeing examples of all three classes from the RGZ DR1 catalogue. The animated gif (from the ICRAR press release) describes how ClaRAN “sees” the example radio galaxy. Please do not click on the link to the animated gif if you suffer from epilepsy or have any issues with flashing images.
As we look towards the future, we look forward to teaching ClaRAN some of
the more complex and exotic radio galaxy structures. For that to happen, we need to assemble much larger samples of more complex radio morphology classifications. With your support of Radio Galaxy Zoo, I am sure that we will get there.
Fun fact: did you know that some of the more obscure bugs in the RGZ DR1 catalogue processing was actually found through training ClaRAN? This is because ClaRAN is a good learner and will learn all the small details that we didn’t initially notice. We only discovered these bugs through some of the funny answers that we got out of some of the early testing of ClaRAN.
Thank you very much again to all our Radio Galaxy Zooites for your support. More information on the ICRAR press release for ClaRAN can be found via this link: https://www.icrar.org/claran/
Gems of the Galaxy Zoos: help pick Radio Galaxy Zoo Gems!
Help vote for Radio Galaxy Zoo Gems!
At the Galaxy Zoos (both at Galaxy Zoo & Radio Galaxy Zoo), we are fizzling with excitement as we prepare for observations using the Advanced Camera for Surveys instrument on board the Hubble Space Telescope. These new Hubble maps will have greater resolution than those that we have from the Sloan Digital Sky Server.
As mentioned by Bill’s blogpost, we have been allocated fewer observing slots than our full list of candidates. Therefore, we invite all of you to help shape the observing priorities of our current target list. You will help determine which host galaxies would gain the most from these Hubble observations (and thus have highest priorities on the target list).
The main science targets specific to these Hubble observations are the host galaxies of Green Double Radio-lobed Active Galactic Nuclei (Green DRAGN — pronounced Green Dragon) and Spiral Double
Radio-lobed Active Galactic Nuclei (S-DRAGN).
Figure 1: Example of a Green DRAGN that is also a Hybrid Morphology Radio Source (HyMoRS) found by Radio Galaxy Zoo (Kapinska, Terentev et al 2017)
Green DRAGN — The prominent green appearance in these DRAGN host galaxies come from the strong [OIII] emission line that dominate the emission in the Sloan r-band. Therefore, these galaxies appear very green in a Sloan 3-colour (g,r,i) image due the lack of equivalently-strong emission in the Sloan g– and i– bands (the blue- and red- filters, respectively). The Green Pea galaxies (Cardamone et al 2009) from the original Galaxy Zoo project are a class of green galaxies that appear to be dominated
by star formation. On the other hand, the Green Bean galaxies (Schirmer et al 2013) are thought to consists of quasar light echoes (eg Galaxy Zoo’s Hanny’s Voorwerp). However, the original Green Bean population show little to no emission at radio wavelengths.
In Radio Galaxy Zoo, we have found a population of Green Bean-like galaxies which host bright radio lobes. Therefore, what sort of feedback are galaxies getting from these “radio-active” Green DRAGNs and how do they relate to the other green galaxies and our understanding of galaxy evolution? Figure 1 shows an example of a Green DRAGN that also happened to be a Hybrid Morphology Radio Galaxy
found by Radio Galaxy Zoo and published by team scientist Anna Kapinska in collaboration with citizen scientist Ivan Terentev (see blogpost on their paper).

Figure 2: An example S-DRAGN that is radio galaxy 0313-192 where VLA observations have been overlayed in red over an HST ACS image. (More details can be found in Bill’s paper: Keel et al 2006)
Spiral DRAGN — Typically, radio galaxies with big radio jets and lobes are hosted by early-type galaxies. Spiral galaxies are often thought to not be “mature” or massive enough to host giant radio lobes. However, a few S-DRAGNs have been found in the past by our very own Bill Keel (Keel et al 2006, see Figure 2) and Minnie Mao (Mao et al 2015). To shed light on this rare phenomena,
we seek your help through Radio Galaxy Zoo and this observing programme to assemble a more statistically significant number of this rare class of objects. Figure 2 shows a combined HST and VLA map of the S-DRAGN
published by Bill in 2006.
We have to finish this priority selection by the 16th February 2018. So, please help vote now by clicking here. We have uploaded the targets in batches of 24 and so please click on all the batches for a view of the full target list. A handy tip for inspecting these images is to ensure that your screen brightness is adjusted to its maximum because many of the host galaxy features can be very faint.
We thank Radio Galaxy Zooites, Jean and Victor, for their immense help with assembling the priority selection project interface. You can track what Hubble is observing by proceding to the Hubble archive link or the Hubble Legacy Archive interface here.
Gems of the Galaxy Zoos – help pick Hubble observations!

Galaxy Zoo and Radio Galaxy Zoo participants have an unusual opportunity to help shape a list of galaxies to be observed by the Hubble Space Telescope, as part of the “Gems of the Galaxy Zoos” project.
The project came about when the Space Telescope Science Institute circulated a message in August of 2017, seeking proposals for a new category of observation – gap-fillers. These projects will provide lists of target objects around the sky for brief observations when high-priority projects leave gaps in the telescope schedule, allowing 10-12 minutes of observation at intermediate places in the sky. Read More…
Radio Galaxy Zoo finds rare HyMoRS!
The following blogpost is from Anna Kapinska about the Radio Galaxy Zoo paper that she published recently with Radio Galaxy Zooite, Ivan Terentev on the first sample of candidate Hybrid Morphology Radio Sources (HyMoRS) from the 1st year of Radio Galaxy Zoo results.
Radio Galaxy Zoo scores another scientific publication! The paper ‘Radio Galaxy Zoo: A search for hybrid morphology radio galaxies’ has been published today in the Astronomical Journal. First of all congratulations to everyone, and what wonderful work from all our citizen scientists and the science team! Special thanks go to Ivan Terentev, one of our very active citizen scientists, whose persistent work on finding and collecting HyMoRS in a discussion thread on RadioTalk (link) without doubt earned the second place in the author list of this paper. But of course the publication wouldn’t be possible without all our volunteers, and special thanks are noted in the paper (check out the Acknowledgements on page 14):
“This publication has been made possible by the participation of more than 11,000 volunteers in the Radio Galaxy Zoo Project. Their contributions are acknowledged at http:// rgzauthors.galaxyzoo.org. We thank the following volunteers, in particular, for their comments on the manuscript or active search for candidate RGZ HyMoRS on RadioTalk: Jean Tate, Tsimafei Matorny, Victor Linares Pagán, Christine Sunjoto, Leonie van Vliet, Claude Cornen, Sam Deen, K.T. Wraight, Chris Molloy, and Philip Dwyer.”
But what are HyMoRS? HYbrid MOrphology Radio Sources, HyMoRS or hybrids for short, are peculiar radio galaxies that show atypical radio morphologies. That is, radio galaxies which we can resolve in our observations come in two principal flavours: 1) FRI – type; and 2) FRII-type — named after two scientists who introduced this classification back in 1974, Berney Fanaroff and Julia Riley [link to paper].

Figure 1. Three main types of radio galaxies. FRI type (3C 296, left panel), FRII type (3C 234, right panel), and a HyMoRS that shows a hybrid radio morphology of FRI on its eastern (left) side and FRII on its western (right) side (RGZ J103435.8+251817, middle panel). The radio emission from the jets is in blue, overlaid on the SDSS true colour images. Credits: Kapinska (based on FIRST/NRAO, SDSS, Leahy+Perley 1991).
Traditionally, FRIs and FRIIs are distinguished by different morphologies observed in radio images, where on the one hand we have archetypal FRIIs showing powerful jets that terminate in so-called hotspots (can be spotted in right panel of Figure 1 as two white bright spots at the ends of the jets), while on the other there are FRIs with their jets often turbulent and brightest close to the host galaxy and its supermassive black hole (left panel of Figure 1). HyMoRS are hybrids, they show both morphologies at the same time, that is they look like FRI on one side and FRII on the other side. Figure 2 shows two examples of the new HyMoRS candidates that Radio Galaxy Zoo identified in this latest paper.

Figure 2. Two new HyMoRS candidates found with Radio Galaxy Zoo: RGZ J150407.5+574918 (left) and RGZ J103435.8+251817 (right). The radio emission from the jets is in blue overlaid on the SDSS true colour images. The inserts show zoom-ins on the HyMoRS’s SDSS images of the hosts galaxies. Credits: Kapinska (based on FIRST/NRAO, SDSS).
How are HyMoRS formed? We still don’t have a very clear answer to this question. The thing is that there may be many reasons why one radio galaxy would have so radically different looking jets. One possibility is that the medium in which the jets travel through (the space around) is different on each side of the galaxy. In this case the FRI morphology could form if the medium is dense or clumpy for one jet, while FRII morphology could form if the medium is smoother or less dense on the other side for the second jet (but watch this space for more work from our science team). But there are also other options. For example, we may simply see the radio galaxy in projection, or we are observing rare events of a radio galaxy switching off, or switching off and on again. The more HyMoRS we know of, the better we can study them and pinpoint the scenarios of how they form.
For example, the science team at the University of Tasmania has produced a simulation of jets from an FRII-type radio galaxy located in the outer regions of a cluster (~550 kpc from the centre) and expanding in a non-uniform cluster environment. The jet on one side propagates into a much denser medium than the jet on the other side. The jets are very powerful (10^38 Watts) and the total simulation time is 310 Myr. The movies display the density changes associated with the jet expansion. Credit goes to Katie Vandorou, Patrick Yates and Stas Shabala for this simulation (link to simulation).
How rare are HyMoRS? We actually don’t really know, and this is because so far there are very few complete surveys of these radio galaxies. Current estimates indicate that they may be comprising less than 1% of the whole radio galaxy population. We are hoping that with Radio Galaxy Zoo and the new-generation telescopes we will be able to finally pin down the HyMoRS population. And our paper is definitely one big step towards that aim. It’s very exciting as with the fantastic efforts of RGZ we now have 25 new HyMoRS candidates — this could possibly double the numbers on known hybrids!”
So well done everyone and let’s keep up the fantastic work! We couldn’t have done it without you 🙂
Anna, Ivan & the coauthors on this latest paper
___________________
The official open access refereed paper can now be found at http://iopscience.iop.org/article/10.3847/1538-3881/aa90b7
The article can also be downloaded from: http://arxiv.org/abs/1711.09611
A CAASTRO story with embedded animation is now available at: http://www.caastro.org/news/2017-hymors
Galaxy Zoo Literature Search
Dear volunteers,
Here at Galaxy Zoo we know that some of you are looking for ways to be more involved in the entire process of making science from your clicks.
So we had an idea…..
The team are currently in the process of writing a paper which in its introduction discusses some of the current assumptions/errors/approximations common among our fellow astronomers when thinking about galaxy morphology and classification. As such we’d like to collect as many papers as possible which do the following things:
- Claim that colour and morphology are equivalent
- Define “early-type” galaxy as any galaxy without visible spiral arms (e.g. our “smooth” category, which can include elliptical galaxies, and smooth disks), rather than as a galaxy that isn’t a disk.
- Define “early-type” galaxy as including Sa spirals as well as lenticular and ellipticals.
- Define “late-type” galaxy as only late-type spirals (e.g. excluding Sa spirals)
- Use colour or spectral type to split galaxies into “early-“ or “late-“ types (or “elliptical” and “spiral”)
- Use the bulge-to-total ratio (or some proxy for it like concentration, or the SDSS “fracDeV” parameter) to place spiral galaxies in a sequence.
The current draft text in the paper which talks about these assumptions is:
“The morphology of a galaxy encodes information about its formation history and evolution through what it reveals about the orbits of the stars in the galaxy, and is known to correlate remarkably well with other physical properties (e.g. Roberts & Haynes 1994). These correlations, along with the ease of automated measurement of colour or spectral type, have resulted in a recent trend for classification on the basis of these properties rather than morphology per se (e.g. Weinmann et al. 2006, van den Bosch et al. 2008, Zehavi et al. 2011). Indeed the strength of the correlation has led some to authors to claim that the correspondance between colour and morphology is so good that that classification by colour alone can be used to replace morphology (e.g. Park & Choi 2005, Faber et al. 2007). Meanwhile the size of modern data sets (e.g. the Main Galaxy Sample of the Sloan Digital Sky Survey, SDSS, Strauss et al. 2002) made the traditional techniques of morphological classification by small numbers of experts implausible. This problem was solved making use of the technique of crowdsourcing by the Galaxy Zoo project (Lintott et al. 2008, 2011). One of the first results from the Galaxy Zoo morphological classifications was to demonstrate on a firm statistical basis that colour and morphology are not equivalent for all galaxies (Bamford et al. 2009, Schawinski et al. 2009, Masters et al. 2010) and that morphology provides complementary information on galaxy populations useful to understand the processes of galaxy evolution. “
and later when talking about the spiral sequence:
“Modern automatic galaxy classification has tended to conflate bulge size alone with spiral type (e.g. Laurikainen et al. 2007, Masters et al. 2010a), and automatic classification of galaxies into “early-” and “late-” types, referring to their location on the Hubble Sequence and based on bulge-total luminosity ratio (B/T ) or some proxy for this through a measure of central concentration, or light profile shape (e.g. Sersic index, as reviewed by Graham & Driver 2005) has become common (e.g. van der Wel et al. 2011). Indeed, Sandage (2005) says this is not new, claiming ”the Hubble system for disk galaxies had its roots in an arrange- ment of spirals in a continuous sequence of decreasing bulge size and increasing presence of condensations over the face of the image that had been devised by Reynolds in 1920.””
We’d like to ask for your help in searching for more examples of these behaviours. We have made a simple Google form, and we ask that you submit any examples you find in the next few weeks.
Some of the papers you find might end up cited in the Galaxy Zoo team paper (please be aware there are rules/guidelines about the appropriate number – we don’t want to have too few; it doesn’t make the point about how widespread this is, and we don’t want to single out specific astronomers, but the journal won’t accept too many either). If there are more papers found than we can use, they will be kept in a list on the Galaxy Zoo website (and we can continue to add to them if needed).
I want to reassure you that helping with this does not mean you have to read the entire extragalactic astronomy literature, or even the entirety of a paper! The best place to look for this information in a paper will be the “Sample Selection”, or “Data” sections. Modern online PDF papers also have excellent search facilities – so searching the text for key words (e.g. “spiral”, “early-type”, “colour/color-selected”) may work extremely well.
We’re happy for you to do this however you like (e.g. Google Scholar is fine), but we’d like you to return the NASA ADS (Astrophysics Data System) URL for the paper you find. You can search ADS here: http://adsabs.harvard.edu/abstract_service.html, and I give examples below of the URL I mean. This makes it easy for us to get the full bibliographic data to add the reference to the paper.
One tip – there are some papers in extragalactic astronomy which are cited by most/many results. A good place to start looking through recent papers would be the citation and reference lists of such papers, which can be found in ADS.
For example:
Strateva et al. 2001 “Color Separation of Galaxy Types in the Sloan Digital Sky Survey Imaging Data”
http://adsabs.harvard.edu/abs/2001AJ….122.1861S is cited by 926 papers, and references 25 – this would be an excellent starting place, and the more papers you read the more mentions you may find other other papers doing similar things.
Other good starting places:
Strauss et al. 2002: “Spectroscopic Target Selection in the Sloan Digital Sky Survey: The Main Galaxy Sample” http://adsabs.harvard.edu/abs/2002AJ….124.1810S
Ironically the papers which cite some of our Galaxy Zoo papers where we demonstrate there are galaxies which are not in the normal correlation between colour and morphology may also be good starting points (some citations to these are along the lines of saying things like: “most galaxies fall into blue=spiral; red=elliptical, a few don’t (cite Galaxy Zoo here), but we’re going to use this definition anyway”.
The initial papers on colour not being the same as morphology are:
Bamford et al. 2009 (281 citations): http://adsabs.harvard.edu/abs/2009MNRAS.393.1324B
Schawinski et al. 2009 (81 citations): http://adsabs.harvard.edu/abs/2009MNRAS.396..818S
Masters et al. 2010 (125 citations): http://adsabs.harvard.edu/abs/2010MNRAS.405..783M
We hope that if several of you take up the challenge, you’ll find different paths through the literature and find lots of different examples for us. Again here’s the link to our Galaxy Zoo Literature Survey.
Thanks for your help!
Karen Masters (Galaxy Zoo Project Scientist)
#GZoo10 Day 2 : Happy Birthday to us
Ten years ago today, I was trying to work out how to deal with the sudden flood of volunteers heading to our site to help explore the Universe. Lots of that traffic came from a BBC News article, so it seems appropriate they’re marking the day with a new piece reflecting on recent results.
BTW – for more on the Hubble paper described in the BBC article, these from @galaxyzoo blog https://t.co/NFghsTJvNx https://t.co/61JARjnHtC https://t.co/KZHum115sr
— William Keel (@NGC3314) July 11, 2017
(As Bill says, you can find out more about those results here on the Galaxy Zoo blog).
We’re ready for day 2 of the Galaxy Zoo 10 workshop at St Catherine’s College in Oxford; it was great to have so many people following along yesterday morning on the Livestream – yesterday’s talks are still up, and today’s schedule is:
9.40am: Karen Masters (Portsmouth)
10.00am: Lucy Fortson (Minnesotta)
10.20am: Hugh Dickinson (Minnesotta)
11.00am: Sam Penny (Portsmouth)
11.20am: Becky Smethurst (Nottingham)
11.40am: Ross Hart (Nottingham)
12 noon: Seb Turner (Liverpool John Moores)
12.20pm: Peter McGill (Oxford).
We’ll blog these talks as they happen here too.
From here one in folks it’s Becky Smethurst taking the reins – once more unto the breach my friends!
We’re kicking off the day with an original science team member: Karen Masters! She’s going to be asking the question: After 10 years of Galaxy Zoo: What Now?
She kicks us off with thinking about how Galaxy Zoo classifications are just as quantitative as an automated computer classification of a galaxy’s morphology – but what can we do to combine these measurements? The problem is that computers which searching for a best fit model can get stuck in what’s called a “local minimum” in parameter space which is not actually the best fit. Combining human interaction with this computer fitting process will help to find the “global minimum” or the true best fit for the model. Karen is showing a new project that is still in the early development stages where volunteers help to fit a model light profile for a galaxy.
.@KarenLMasters about an exciting new project to combine Galaxy Zoo with quantitative morphology #GZoo10 pic.twitter.com/VfLetYsIyc
— galaxyzoo (@galaxyzoo) July 11, 2017
Karen now segways into the idea that colour ≠ morphology, which was one of the first results from Galaxy Zoo.
.@KarenLMasters explaining the origin of the confusion that colour=morphology #GZoo10 pic.twitter.com/a7qKYRfRtD
— galaxyzoo (@galaxyzoo) July 11, 2017
She’s now talking about how we need to go one step beyond the visual morphologies we have, to classify how the stars are actually rotating. New galaxy surveys, such as MaNGA that Karen is working on, are taking many spectra across the whole galaxy to get rotation maps. We can then classify these rotation maps to understand a galaxy’s history – less ordered rotation suggests that a galaxy’s disk has been disturbed by something like a merger or interaction. This is really helpful to astronomers to be able to figure this out, especially if there’s no clues in the visual morphology that an interaction or merger is happening.
Karen ends her wonderful talk by discussing how we can all get more students involved with Galaxy Zoo and astronomy as well. Galaxy Zoo is often used in Astronomy 101 classes at universities, as well as in schools – so how do we engage more with this side of the Galaxy Zoo community?
Next up this morning is Lucy Fortson talking about “The evolution of a Galaxy Zoo team member.” Ten years ago Lucy was working at the Adler Planetarium in Chicago and was aware that the best research model for museums was to get the public to participate in it – so jumped at the chance to join the Galaxy Zoo research team! She’s now going to be giving us a round up of everything going on in the group at Minnesota – one of the hubs for the Galaxy Zoo research team.
Next is @LucyFortson on the work of the team at the University of Minnesota in #galaxyzoo #GZoo10 pic.twitter.com/sT35I9KKxi
— galaxyzoo (@galaxyzoo) July 11, 2017
Mel Galloway’s work comparing the UKIDSS (infrared images) and SDSS (optical images) Galaxy Zoo classifications – how does the morphology of a galaxy change with wavelength? Mel has also worked with the Galaxy Zoo Hubble classifications looking at how disk galaxies evolve and become passive (i.e. non star forming). The problem was that the number of disks drops out at the high redshifts that the Hubble Space Telescope can target, so makes the sample of disks incomplete. This ended up with a new offshoot project classifying disk galaxies lovingly titled Save Mel’s Thesis! With these classifications providing a more complete sample, Mel managed to show how the the amount of passive disks increased from 6 billion years ago to the present day. Not only that, she also showed that more massive galaxies are more likely to keep their disks after they stop forming stars as well.
Now we’re all getting emotional because Lucy’s brought up Kyle Willett who recently left astronomy to work in the data science industry. But where would Galaxy Zoo be without Kyle?! He not only published a lot of the data release papers for Galaxy Zoo but also kept up the site maintenance and even ran the kaggle competition we held for machine classifications of galaxies.
Speaking of machine classifications of galaxies – did someone say Melanie Beck?! Melanie is working on using machine learning in conjunction with the user classifications to complete Galaxy Zoo much quicker by retiring the easy subjects much quicker, leaving the users with the interesting and difficult things to classify.
.@LucyFortson presenting the work of @highzgal on combining machine learning with Galaxy Zoo classifications #GZoo10 pic.twitter.com/Nqc87wMrv2
— galaxyzoo (@galaxyzoo) July 11, 2017
This is going to be really important in the future when new telescopes like the LSST start observing when we’ll have almost 1 billion images of galaxies! If the computers are working on the easy stuff, say 90% of the images, users will still be left with 1 million more interesting things to classify!
The next Minnesota person is Hugh Dickinson – but he’s in the room, so now we’re hearing from him personally. Hugh is working on the classifications from Galaxy Zoo Illustris – the first time users have been asked to classify galaxies from a different universe – albeit a universe that only exists inside a computer! Illustris is a simulation of galaxies which is one of the most realistic simualtions to date; it’s high resolution and includes all the ingredients for a Universe such as dark matter, stellar processes, feedback and gas cooling.
Next is Hugh Dickinson on results from using simulated galaxies in Galaxy Zoo #GZoo10 pic.twitter.com/qAlwVkrE5V
— galaxyzoo (@galaxyzoo) July 11, 2017
But why is it important to classify what are essentially “fake” galaxies? Well with a simulation we know exactly what the history of a galaxy is throughout the entire simulated life of the Universe, so if we’re getting the same morphologies as we see in the Universe then we know that the Physics we’ve assumed to make this simulated universe are right. It can also help highlight the links between a galaxy’s visual appearance and its dynamical history. So although it might seem weird classifying something that doesn’t really exist, those classifications are extremely helpful to astronomers to help down pin down the Physics that is occurring in the Universe.
So the first thing that Hugh has looked at is the first question in the Galaxy Zoo tree: smooth or featured? And the bad news is that the classifications of the simulation images don’t match the real classifications of galaxies from Galaxy Zoo 2.
We find that simulated and real galaxies indicate almost opposite smooth/features fractions. There is a match only at higher masses #GZoo10 pic.twitter.com/fN90GuKcmv
— galaxyzoo (@galaxyzoo) July 11, 2017
This means that there’s an issue with the simulations – investigating it further they found that there is actually very good agreement between the classifications for higher mass galaxies (> 10^11 solar masses) where the same number of smooth galaxies are seen. For lower mass galaxies though there are a lot more featured things in the simulations than in the real Universe. So, from this preliminary study Hugh’s figured out that we’ll only be able to compare the detailed structures of simulated and real galaxies of high mass – so now these are back being classified right now on the Galaxy Zoo site to get answers to all the further questions about spiral arms, bars etc. So please keep classifying!
Hugh is now telling us all about one of our newest projects: Galaxy Nurseries! Users look at the spectrum of a galaxy and are asked whether the emission they’re seeing in the plot is a real feature or not. The data is a bit messy, so this is not an ideal task for a computer but perfect for a human! There’s a lot to be done with this project but Hugh is excited to see the classifications come through.
Time for coffee for us now – we need caffeine to keep up this level of science discussion!
Next up for our listening pleasure is Sam Penny from the University of Portsmouth.
Next is @astro_hedgehog on dwarf galaxies and MaNGA @sdssurveys #GZoo10 pic.twitter.com/xSPYAo6OpV
— galaxyzoo (@galaxyzoo) July 11, 2017
She’s going to be giving us an overview of the MaNGA survey, which is a new survey looking at the kinematics of galaxies by taking lots of spectra for each galaxy in a bundle. How are we going to integrate this then with Galaxy Zoo? Currently Sam works on very low mass non star forming galaxies which tend to be quite low brightness so aren’t always the easiest to visually classify. So she’s using the kinematic information that MaNGA provides to reveal how these galaxies have evolved. But she wants to know is there a link between the kinematics and the morphology of the galaxies? That way, if we don’t have kinematics for some galaxies will we still be able to pick these galaxies out?
Sam’s other interest is void galaxies; these are found isolated from other galaxies in extremely low dense environments. Surprisingly for galaxies that have been isolated from other galaxies their entire lives, some of them are very massive, very red (i.e. no longer star forming) and have disks. So how did they get so massive on their own? The most massive galaxies in the Universe are thought to build up through mergers – but if these galaxies are isolated then this doesn’t seem to be a possibility for these objects!
This is Chris Lintott taking back over to blog Becky’s talk.
She’s discussing our elephant in the room – the fact that we don’t deal with kinematic morphologies; in other words, we classify galaxies by how they look, not how the stars and gas move within them.
Before that, though, she’s pointing out that the clean samples we assemble from our data – which require a threshold of, say, 80% of people to agree on a classification before a galaxy makes it in – throw out a huge number of galaxies. That works, says Becky, if you’re trying to assemble a sample of discrete bins, like the categories on the Hubble diagram, and not a continuous range of types of galaxies.
But! There’s a catch. If you care about kinematic morphology, there really is a true binary. Things are rotating as a disk or they are not. (The audience seems not necessarily to agree on this point; we’ll see what happens when we get to questions). To study kinematics we can use instruments like MaNGA, which I hope Becky described above during Sam’s talk – Becky tested us and though the majority could distinguish a rotating smooth galaxy from a non-rotating smooth galaxy, it certainly isn’t easy just by looking. (And we probably shouldn’t draw conclusions from a sample of one).
.@becky1505 testing us on identifying the kinematics of galaxies by the visual inspection of galaxy morphologies. We failed. #GZoo10 pic.twitter.com/OIQkD7GKgY
— galaxyzoo (@galaxyzoo) July 11, 2017
Becky reckons that only 20% of Galaxy Zoo smooth galaxies are ‘true’ ellipticals – those that don’t have a hidden disk-like rotation inside. How will this affect Becky’s work on fitting star formation histories? She does this using a code called StarPy, which uses statistics to decide when a galaxy started to stop star-formation and how fast that ‘quenching’ is happening. (There’s a nice description of StarPy on the blog here).
Using MaNGA to divide galaxies not by visual morphology, but by rotation, Becky has run Starpy and finds differences. Non-regular rotators – what we might call ‘true ellipticals’ – quench either quite fast or very fast; there were a bunch of smooth galaxies that only quenched slowly, but these now seem to be the regular rotators; disks hiding amongst the Galaxy Zoo smooth sample.
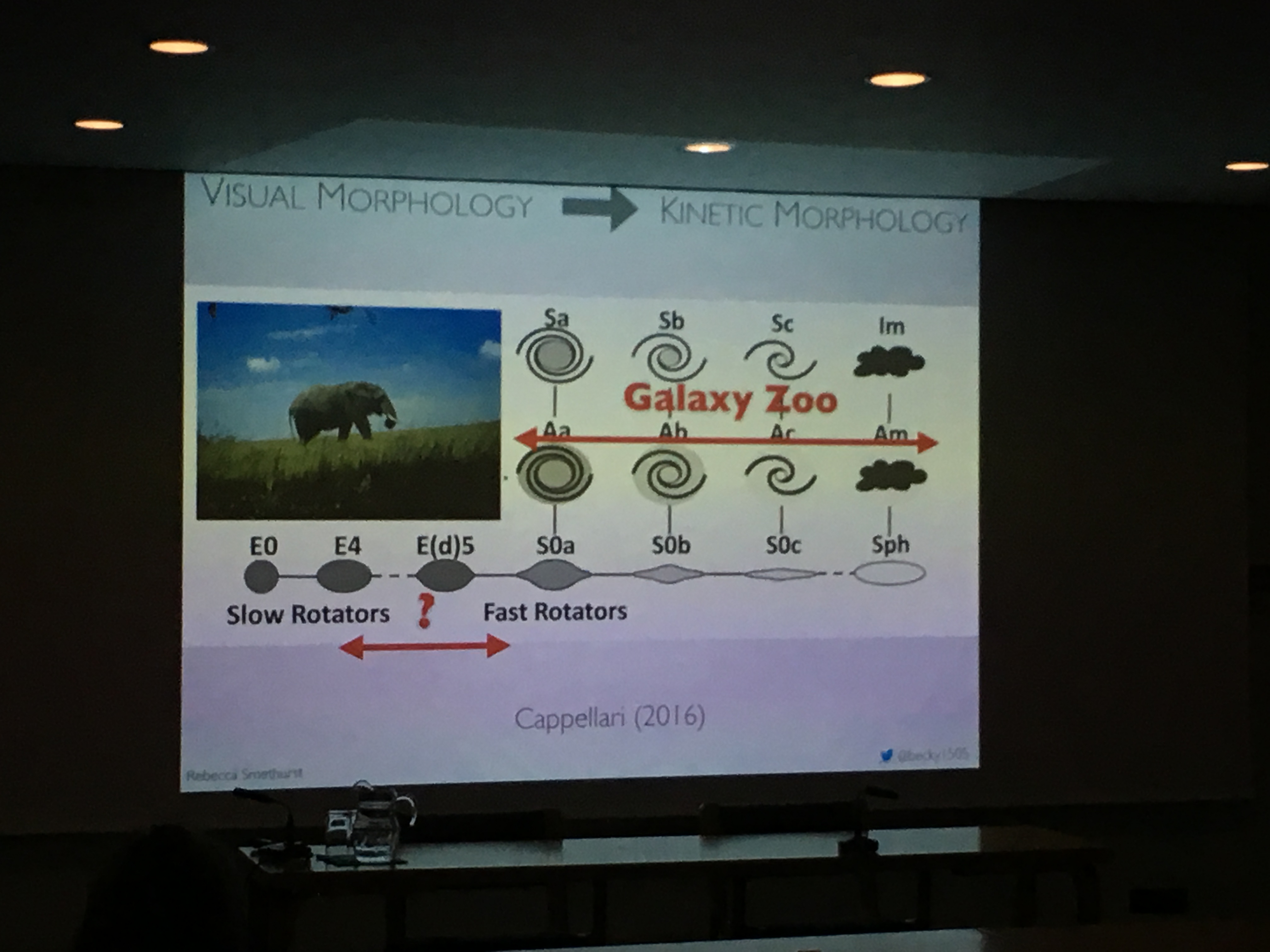
Becky finishes with this diagram, from a recent review of kinematic morphologies. She’s added the location of the elephant – she feels we’re good at distinguishing spirals but need to talk about the smooth ones. In questions, Karen reckons we can tell the difference visually, Jean Tate wanted confirmation that lenticulars rotate (they do!), and I reckon we need to think hard about statistics.
Becky is back!
Next up is Ross Hart who’s telling us all about his work for correcting for biases in Galaxy Zoo 2 data to get out a nice complete sample of spiral galaxies. The problem is that at greater distances it becomes harder to spot spiral arms as things get fainter.
#gzoo10 Hugging spiral arms all conference pic.twitter.com/WWTOlg1Bqs
— Alice Sheppard (@PenguinGalaxy) July 11, 2017
Ross’s code does a really nice job of recovering lots of spiral galaxies that would’ve been missed otherwise in the catalogue. Now we’ve got this catalogue we can use it to study the properties of spirals with arm number – turns out many armed spirals look a lot bluer than typical 2 armed spirals. Despite the fact that they appear blue (i.e. forming lots of hot, young, blue stars!), when Ross measures the star formation rate of these galaxies there is no dependance with arm number. But, he does find that more armed spirals have more hydrogen gas than 2 armed spirals, so might have more fuel for star formation in the future.
So what is actually happening in the spiral arms? Ross is now using an automated method to identify where the spiral arms in galaxies are called SpArcFiRe. Once the spiral arm locations have been identified, we can take off their light from the rest of the disk and just study what’s going on in the spiral arms and disk separately. Ross is currently working on these results but has some interesting preliminary results – so watch this space!
Now for something completely different! We’ve got Sebastian Turner from Liverpool John Moores University telling us all about automating galaxy classifications.
Our final speaker for today is @sebturne on using machine learning in classifying galaxies #GZoo10 pic.twitter.com/MoCS3Amyqo
— galaxyzoo (@galaxyzoo) July 11, 2017
He’s asking what are we going to do moving forward? How will we merge the efforts of computers and humans? Seb is working on using statistical clustering methods to pick out information from the data we already have about galaxies. Clustering methods can pick out groupings of features in a sample – Seb feeds in information about the mass, colour and shape of a galaxy and the machine returns how many groupings it thinks there are in this multi-dimension parameter space. This can tell us something more about galaxy evolution because as humans we could never visualise this multi-dimensional space. Seb is showing us how the clustering algorithm picks up the areas of the colour magnitude diagram that we’re used to including the blue cloud, red sequence and green valley. The groups it picks out also correlate nicely with Hubble type morphology as well which is encouraging! There’s a lot more work we can do with this including using the Galaxy Zoo classifications as an input to the algorithm.
Ross wanted to know if we could input kinematics into this as well? Seb definitely thinks it’s possible. Brooke then asked about how it was weird the algorithm picked out two groups in the blue cloud before it picked out a group for the green valley. Seb reckons a big issue is that the algorithm tries to equalise the numbers in the groups and there’s just so many galaxies in the blue cloud.
Next up is a summer student at the University of Oxford: Peter McGill. He’s been looking at star formation histories of galaxies (like me!) but in galaxies at greater distance (high redshift) in the COSMOS survey with images taken by the Hubble Space Telescope.
Oops turns out @sebturne was not our final speaker! It is @petermcgill94 on the star formation histories out to a redshift of z~1 #GZoo10 pic.twitter.com/UFFMnO1a82
— galaxyzoo (@galaxyzoo) July 11, 2017
In particular he’s focussing on figuring out what is stopping star formation (or quenching it) in the high redshift Universe. He’s using Starpy again (see Becky’s talk above!) to model the star formation history but has changed Starpy to take colours from the Hubble telescope rather than the SDSS. He’s looking at how these star formation histories change at different redshifts in the COSMOS survey and in comparison the results in the local Universe with SDSS. He’s showing plots where you can see how the rate that the star formation quenches at gets quicker for galaxies at higher redshift. His future work includes figuring out to include galaxy environment in these studies and changing the method to use a better algorithm to explore the parameter space!
Now we’re off to lunch and afterwards we’ll be having “un-conference” sessions where we’ll have lots of discussions. I’ll be live blogging later on when we report back – see you then internet!
We’re back! We’ve had a very productive afternoon discussing all the weird and wonderful things.
First up, Chris is telling us about a discussion half the team had about a paper draft from four years ago that we forgot existed. It got left by the wayside when the team ran into some problems with completeness of a spiral sample – however Ross’s current work has solved that for us! So we’re going to try completing it as a team again so watch this space.
Steven is now telling us about a session they had about integrating machine learning algorithms with Galaxy Zoo classifications (and Zooniverse classifications as a whole). So how will this affect the interaction of the volunteers with the site and the quality of the data we get out? The aim of this is to speed up classifications (for GZ2 from 6 months –> 1 month) since we’re moving into an era of even larger data sets. It will also hopefully mean the machine will do the boring stuff and the interesting stuff gets left in for the users (although that will vary with project). We have to be careful though not to put in too many good images though because research has shown there is a sweet spot for the amount of boring classifications to keep people classifying on the site. Also we want to make sure we’re still showing a representative sample of objects so that the public logging onto the site don’t get a biased view of what galaxies look like in the Universe. Could we have somewhere we still put retired (either by the machine or by humans) images for users to still explore these? The discussion then came back to what the main science goal of the Galaxy Zoo project is – is the final goal science or to make an interesting data set?
There was a hack session that also occurred to get a master data table for the MaNGA Galaxy Zoo classifications. We have them all, they’re just a bit scattered all over the place and need concatenate into one giant table.
Then the science team had a discussion about fast and slow rotators – can we actually do kinematic classifications by eye? We think we’re going to challenge the astronomical community to test this.
Then the science team had a talk about Talk. The discussion was focussed on the importance of needing to engage with the Galaxy Zoo community.
There was also another hack taking place this afternoon playing around with the Galaxy Zoo:3D data. Some of us got to grips with the data and tried to make some nice plots. One thing we did realise is that it might be worthwhile in getting about a third of the sample classified a bit further for better statistics.
We had a discussion about one of the tools that we use as a team to infer star formation histories; Starpy. We want to update this code to use a more robust statistical algorithm to get results.
Whilst that was going on, there was also a discussion about how to engage more with undergraduate students. One idea was to have a summer camp with undergraduates who will be engaging in research in the future – teaching them about citizen science, interacting with data, coding skills with a focus on Python – similar to the .Astronomy summer camp or the LSST data camp. Perhaps this could be tied in each year with a science team meeting? Also users may also enjoy this type of summer camp idea as well!
And that’s it for science for the day! We have our formal conference dinner tonight though so we’re all looking forward to socialising over a delicious dinner. Until next time internet!
Welcome to #GZoo10 : Day 1
It’s the day before Galaxy Zoo’s tenth birthday, and the team have gathered in Oxford for three days of discussing science and our plans for the future. Because it’s Galaxy Zoo, we’re inviting any of you who are interested to follow along online.

Members of the Galaxy Zoo team relax before the start of their meeting in an Oxford pub.
The mornings will be taken up with talks from team members. Today’s schedule is :
10am : Chris Lintott (Oxford)
10.20am: Lee Kelvin (Liverpool John Moores)
11am: Steven Bamford (Nottingham)
11.20am: Lucy Newnham (Portsmouth)
11.40am: Sandor Kruk (Oxford)
12 noon: Bill Keel (Alabama)
All the talks will be available via Oxford’ LiveStream account here. You can ask us questions using the #GZoo10 hashtag on Twitter – we will make sure someone in the audience at each session is watching so comments online make it into the room.
The afternoon will be an unconference and hack session, with the team debating the issues raised during the day and getting to work together. These sessions won’t be streamed, but we will blog about what’s going on.
It’s Becky Smethurst blogging from here on in folks…
So we’ve kicked off the day with our fearless leader of the Zooniverse, Chris Lintott, reminding us that on this day 10 years ago the team were having conversations about how it would be amazing if they could get 10,000 people to help classify. Chris is still amazed that we’re here 10 years later with over 400,000 of you.
I am genuinely astonished to be hosting the tenth anniversary workshop for @galaxyzoo. Less astonishing: meeting in a pub. #gzoo10
— chrislintott (@chrislintott) July 9, 2017
Chris is running through some of the modes in which we work with the Galaxy Zoo data. The first is looking at traditional morphologies, which the project was designed to do, like bars and spirals. The second is “distraction mode” where we’re all distracted by the serendipitous discoveries that the users make which we weren’t expecting, like the Voørwerpjes and the green peas. The final mode is the modelling mode, where we’re fitting models to the Galaxy Zoo data to explain something about the Universe. This mode also includes the amazing work with classifications of simulated galaxy images that are ongoing on the Galaxy Zoo site right now!
One of the questions from the audience for Chris is: “Why have the serendipitous discoveries dried up on Galaxy Zoo?” For one thing Chris thinks that one issue is that is takes so long to follow up on these discoveries – we’re still working on the Voørwerpjes! – but one thing we don’t have with the current images on the site (GAMA and KiDS etc.) is a link to the science survey site where the images come from. We had that with the original Sloan Digital Sky Survey (SDSS) images in Galaxy Zoo 1 & 2 which allowed the users to explore the data themselves and flag up something interesting.
Up next is one of the newest members to the Galaxy Zoo team: Lee Kelvin! He’s telling us about his work with the Galaxy Zoo classifications of the GAMA and KiDS survey images which have just been classified by users on the site. The special thing about GAMA is that it’s multi-wavelength; it takes images in various bands across the spectrum, from the ultra-violet to the infra-red. This is important because, as Lee points out, the morphology of a galaxy changes a lot across different wavelengths.
Galaxies look very different in infrared versus visible light …. #GZoo10 pic.twitter.com/eASGpPYiIh
— Alice Sheppard (@PenguinGalaxy) July 10, 2017
GAMA also has cross-over with the KiDS survey (the main role for which is to map the locations of gravitational lenses in the Universe, like those users hunted for in Space Warps!) which has much higher resolution than the SDSS images originally in GZ1 & GZ2. This means they’re perfect for classifying morphologies because more detailed features are resolved. These images are on the site right now – which means lots of pretty pictures for us to classify! These classifications give the team a wealth of information on the galaxies in these surveys – especially when users flag the interesting cases on Talk.
Most discussed galaxies from the @galaxyzoo GAMA sample – interesting difference from what team might pick #gzoo10 pic.twitter.com/hmUsq2KJZR
— galaxyzoo (@galaxyzoo) July 10, 2017
The early results from these classifications with the images from KiDS look very promising but Lee says there’s lots more work to be done! Including setting up a follow-up Zooniverse project trying to distinguish between true smooth elliptical shaped galaxies and disk galaxies that look smooth – so look out for that project going live in the next couple of months!
We’re back and caffeinated after a refreshing coffee break! Now Steven Bamford has taken the stand and is talking to us about the next steps for morphology studies with Galaxy Zoo.
.@thebamf talking about the next steps in galaxy morphology #gzoo10 pic.twitter.com/4wOqQXMKIC
— galaxyzoo (@galaxyzoo) July 10, 2017
He starts us off by reminding us that we can’t just split galaxies into spiral and elliptical galaxies anymore – it’s a lot more complicated than that with a whole evolutionary sequence of smooth disk galaxies between the pure elliptical and pure spiral galaxy sequences. It’s therefore really important to get both visual classifications from Galaxy Zoo but also quantitative morphologies. A quantitative approach is where you analyse an image to reduce the description of a galaxy down to a number – for example, how disturbed or asymmetric a galaxy is. Steven is explaining how you can do this by making a model of a galaxy’s light and subtracting off the original image and analysing what you’re left with. The problem is that the models are tidy but the galaxies are messy! Deciding which model to use is very difficult but that’s where the Galaxy Zoo classifications come in – they can be used as prior information to decide which model to use.
.@thebamf on using non-parametric fitting to model galaxies #gzoo10 pic.twitter.com/s6qne1yZR2
— galaxyzoo (@galaxyzoo) July 10, 2017
Steven explains the reason why we actually want to do all this model fitting is because we care about population statistics. Sometimes we don’t care about individual objects and we want to look at the big picture – to do that we need to reduce all that information down as much as we can.
Next up is one of the newest additions to the Galaxy Zoo team, Lucy Newnham a PhD Student at Portsmouth! She’s giving us a nice introduction to the big picture of galaxy evolution and how galaxies stop star forming as they evolve. She’s particularly focussing on barred galaxies and whether the bar can cause this shut down of star formation.
Next is @LucyNewnham1 on gas in barred galaxies and how can bars switch off starformation #gzoo10 pic.twitter.com/eIPpwF9PKW
— galaxyzoo (@galaxyzoo) July 10, 2017
She’s done some follow up observations of some barred galaxies picked out by Galaxy Zoo using radio telescopes! Ionised hydrogen gas emits a very specific wavelength of light in the radio part of the spectrum (21cm) – so if you can detect emission with radio telescopes at these wavelengths it means there is hydrogen gas there to fuel star formation. It took 115 hours total observing time with the VLA and GMRT to get data for just 7 galaxies! The first one she’s reduced the data for is UGC9362 and she’s found that there is a hole in the gas in the centre of the galaxy where the bar is. She thinks that means that since the bar is rotating with the galaxy, it has carved out a hole in the gas as it does so and used up all the gas needed for star formation.
The next question Lucy is trying to answer is if the strength of the spiral arms is affecting the star formation in a galaxy? To quantify the strength of the spiral arms, Lucy is using the Galaxy Zoo classifications – where more people agree that a galaxy has spiral arms the stronger the spiral arms will be! Lucy has now looked at trends in galaxy properties with the strength of the spiral arms showing us a plot that she even made this morning! LIVE SCIENCE EVERYBODY!
Taking the stand now is another PhD student, Sandor Kruk, who will be continuing this barred galaxy theme: “Dealing with bars… and other mess”. He clarifies that when he refers to “mess” he means other morphological features!
There really are a lot of bars in #gzoo10 pic.twitter.com/YsNTevRCaK
— Alice Sheppard (@PenguinGalaxy) July 10, 2017
Again, he’s focussing on this problem of what makes galaxies stop forming stars. Earlier results from Galaxy Zoo that Karen Masters worked on back in 2012 suggested that bars were a likely culprit. Sandor is now following up on this work to split the galaxy light into the separate components: bar, disk and bulge. Looking at the colour of this light will let us know if that part is star forming: red things are old, with little star formation and blue things are young, with recent star formation. To split this light he had to model the light of over 3500 galaxies! That’s a mammoth effort, but it’s paid off because he’s found that there is a difference between the colours of disks in galaxies with and without bars!
Whilst doing all this modelling, along the way he also made a serendipitous discovery: that some of the bars were offset from the centre of the disks. This is weird – it means that perhaps these galaxies have had an interaction with another galaxy which has shifted everything around. Turns out though that some of these objects had already been flagged in talk by the users! Makes us wonder what else is hiding in there that the team hasn’t yet seen!
Interesting @kruksandor‘s offset bars (https://t.co/5IGeHajUmf) were flagged in Talk years ago. What else is hiding? #gzoo10
— chrislintott (@chrislintott) July 10, 2017
Well Sandor reckons we should start with some of the questions of the Galaxy Zoo decision tree that the team haven’t yet had chance to look at. For example, what shape is the bulge of the galaxy – boxy or round? Does the galaxy have a ring? While Sandor has been fitting all of his 3500 galaxies (some barred and some unbarred as a control sample) for his bar study, he’s been getting some ideas for how we can tackle these questions – so watch this space!
So next up is one of the original science team members, Bill Keel! He’s sort of become the curator of the objects in Galaxy Zoo which don’t fit into any of the classifications we ask about on the site. He’ll be telling us specifically about the Voørwerpjes (i.e. ionization echos). The first one was flagged on August 13th 2007 (another 10 year anniversary coming up, mark it in your calendars!) by one of the volunteers who brought an unusual blue smudge below a galaxy to the team’s attention. Bill is now telling us how they figured out that the weird blue smudge near the galaxy turned out to be a gas cloud which had been ionised by emission from the active supermassive black hole in the centre of the nearby galaxy. We can tell this by looking at the spectrum of these objects – where we split the light into its component wavelengths to spot specific elements and molecules.
Few ‘Wow’ moments in my science (mostly hope for ‘Hmm…interesting’) but seeing the Voorwerp spectrum @NGC3314 is showing was one #GZoo10
— chrislintott (@chrislintott) July 10, 2017
After identifying what this first object was, the users then found more! Bill ended up doing follow up observations on 20 of these objects – including 8 followed up with the Hubble Space Telescope. Turns out NGC7252, a galaxy that astronomers have been studying for 30 years, even has one of these ionised clouds!
Lots to find out about astronomically objects like Hanny’s Voorwerp #GZoo10 Magnetic fields probably involved pic.twitter.com/AZ78twTcHU
— Alice Sheppard (@PenguinGalaxy) July 10, 2017
The search continues for more of these objects – including another one flagged by a user in February 2017 in the current data being classified on Galaxy Zoo. So keep a weather eye out people!
Thank you @NGC3314 for thanking the many volunteers (inc me, my one claim to fame) who found Voorwerpjes! #GZoo10
— Alice Sheppard (@PenguinGalaxy) July 10, 2017
We’re now going to open up the conference to discussion – between the team that are here and you following along online! If you’d like to ask a question or make a comment for discussion – either post it here on the blog or on Twitter with #GZoo10.
The discussion so far has covered how we consider more detailed features of a galaxy and how galaxy simulations will tie in with what we do in the future. We’re also starting the discussion of how the Galaxy Zoo site will be restructured in the future as we move to the new Zooniverse web platform – exciting!
Now we’re all off to lunch to fuel ourselves for a long afternoon of discussion and unconferencing! See you all in an hour – until then, keep tweeting!
At the high table #Gzoo10 pic.twitter.com/GbhSOUsrH2
— Carie Cardamone (@cariecardamone) July 10, 2017
Unconference session ideas at #GZoo10 pic.twitter.com/tszcYseWtS
— galaxyzoo (@galaxyzoo) July 10, 2017
We are back! After an afternoon of “un-conferencing” where we all suggest sessions for discussion and schedule them on the fly.
We first talked about what science we’re going to do with your classifications on the infrared images from the UKIDSS sample. We want to compare how the shape of galaxies changes from the optical to the infrared but it gets difficult because galaxies tend to be fainter and smaller in the infrared. A lot of us are keen to study how the number of bars changes from optical wavelengths to infrared wavelengths. There are some studies showing that bars disappear in the infrared, but there are also some that show that bars appear in the infrared where there are none in the optical. One of the Galaxy Zoo PhD students, Mel Galloway, has already had a quick look at this and we discussed where to take this work next! First thing first though – releasing the classifications as a data table to the public.
Our next discussion session was about the future of the Galaxy Zoo classification cite. How are we going to ask the users to classify the galaxies? The current mode is the classification tree that we get users to walk through and answer each question for every galaxy. This is very difficult to analyse at the end of the project though. So we discussed changing the interface to either (i) single binary questions about each galaxy, e.g. Bar or no bar? Smooth or featured? (ii) A survey project similar to the interface for Snapshot Serengeti which presents all the options for a galaxy at once, (iii) Lots of mini projects which are all offshoots of Galaxy Zoo focussing on one specific science question, or (iv) pairwise classification where we show two images of galaxies and ask which is more featured etc. There were many opinions about what the best way of doing this but we’d also love to hear your thoughts!
Later on we had an “alpha” test of a revamped Galaxy Zoo project which is survey style – it took people a while to get used to but people did seem to like it! There was also a lot of feedback but it was good to get the discussion flowing about what classifiers would like and what researchers would need.
There was also a discussion about how to study bars with the classifications from Galaxy Zoo. It’s a little difficult to pick stuff out, especially the weaker bars. One of the ways astronomers tend to find bars (e.g. when Galaxy Zoo classifications don’t exist for their sample!) is to fit light profiles to the disk of galaxies and take that model light off the original image. What you’re left with is called a “residual” – light that you didn’t account for, i.e. light from a bar. So there was a discussion about making an offshoot Zooniverse project classifying the residual light images to find weak bars.
Ross Hart then led a discussion about his new way of debiasing the Galaxy Zoo classifications to take into account the distance to galaxies and the fact that features get lost. He can recover lots more spirals with his new method. The table we link to on the Galaxy Zoo data page now has his debiased data table linked first.
We also had a discussion session about the outreach project Tactile Universe – which is a project engaging the blind community with astronomy. They’ve been 3D printing images of galaxies – the brightness being the third axis! We’d love to be able to make a tactile Galaxy Zoo but we have to wait for the tactile screen technology that we’d need to be able to do it! Looks like we’ve got our first session for our Galaxy Zoo Twentieth Anniversary Conference – watch this space #GZoo20.
#GZoo10 Learning about the Tactile Universe. Wonderful project https://t.co/LN5dAQtGnA pic.twitter.com/uJ4S8louYG
— Alice Sheppard (@PenguinGalaxy) July 10, 2017
Now we’ve finished up with the discussion all about the science, we get a treat at the end of the day! Our reward is that our very own Grant Miller has come to tell us all Tales From the Zooniverse! He’s telling us all about his first day on the job in the Zooniverse and how he realised it was going to be a great job when he went into his first meeting all about penguins with the Zooniverse’s Tom Hart! He is now showcasing how amazing the Zooniverse project builder is and is currently trying to build the original Galaxy Zoo project with it in under 3 minutes! And I can tell you: Reader, he managed it! He’s now telling us about his top picks for the Top 10 Zooniverse projects you’ve never heard of:
10) Monopole Quest
9) Expert Smooth/Not
8) Letters to Ryan
7) Bash The Bug
6) Faces of the World
5) The Planetary Response Network
4) Beluga Bits
3) Supernova Hunters
2) Family Certificates
1) Grant can’t name the top one! There’s so many on there now that Grant doesn’t know all of the projects on there (he used to know all the researchers of the projects but not anymore!) – 4700 new projects created since the project builder was launched. 47 of these have been fully launched as new projects, with 31 awaiting launch now.
His take home point: a LOT can happen in ten years!
Introducing the 100th Zooniverse Project: Galaxy Nurseries
It is my pleasure to announce the launch of a brand new Zooniverse project: Galaxy Nurseries. By taking part in this project, volunteers will help us measure the distances of thousands of galaxies, using their spectra. Before I tell you more about the new project and the fascinating science that you will be helping with, I have an announcement to make. Galaxy Nurseries is actually the 100th Zooniverse project, and we’re launching it in the year that Galaxy Zoo (the project that started the Zooniverse phenomenon) celebrates its 10 year anniversary. We can’t think of a better birthday present than a brand new galaxy project!
To celebrate these watersheds in the histories of the Zooniverse and Galaxy Zoo, we’re issuing a special challenge. Can you complete Galaxy Nurseries – the 100th Zooniverse project – in just 100 hours? We think you can do it. Prove us right!
Back to the science! What is Galaxy Nurseries? The main goal of this new project is to discover thousands of new baby galaxies in the distant Universe, using the light they emitted when the Universe was only half of its current age. Accurately measuring the distances to these galaxies is crucial, but this is not an easy task! To measure distances, images are not sufficient, and we need to analyze galaxy spectra. A spectrum is produced by decomposing the light that enters a telescope camera into its many different colors (or wavelengths). This is similar to the way that water droplets split white light into the beautiful colors of a rainbow after a storm.
The data that we use in this project come from the WISP survey. The “WISP” part stands for WFC3 IR Spectroscopic Parallel. This project uses the Wide Field Camera 3 carried by the Hubble Space Telescope to capture both images and spectra of hundreds of regions in the sky. These data allow us to find new galaxies (from the images) and simultaneously measure their distances (using the spectra).

This animation shows how a galaxy’s white light going through a prism gets decomposed into all its colors. Like the rainbow! The figure shows how the different colors end up in different positions. In this example violet/blue toward the bottom, orange/red toward the top. At each color, we have an image of the galaxy. When we sum the intensity at any given color, we obtained the spectrum to the right.
How do we do that? We need to identify features called “emission lines” in galaxy spectra. Emission lines appear as peaks in the spectrum and are produced when the presence of certain atomic elements in a galaxy (for example oxygen, or hydrogen), cause it to emit light much more strongly at a specific wavelength. The laws of physics tell us the exact wavelengths at which specific elements produce emission lines. We can use that information to tell how fast the galaxy is moving away from us by comparing the color of the emission line we actually measure with the color we know it had when it was produced. In the same way that the Doppler effect changes the apparent pitch of an ambulance’s siren as it approaches or recedes, the apparent color of an emission line depends on the speed of the galaxy that produced it. Then, we can relate the speed of the receding galaxy to how far it is from us through Edwin Hubble’s famous law.
The real trick is finding the emission line features in the galaxy spectra. Like many modern scientific experiments, we have written computer code that tries to identify these lines for us, but because our automatic line finder is only a machine, the code produces many bogus detections. It turns out that the visual processing power and critical thinking that human beings bring to bear is ideally suited for filtering out these bogus detections. By helping us to spot and eliminate the false positives, you will help us find galaxies that are some of the youngest and smallest that have ever been discovered. In addition, we can use your classifications to create a next-generation galaxy and line detection algorithm that is much less susceptible to being fooled and generating spurious detections. All your work will also be very valuable for the new NASA WFIRST telescope and for the ESA/NASA Euclid mission, which both will be launched in the coming decade.
Emission lines in a galaxy’s spectrum can tell us about much more than “just” its distance. For example, the presence of hydrogen and oxygen lines tells us that the galaxy contains very young, newborn stars. Only these stars are hot enough to warm the surrounding gas to sufficiently high temperatures that some of these lines appear. By examining emission lines we can also learn what kind of elements were already present and in what relative proportions. We too are “star-stuff”, and by looking at these young galaxies we are following the earliest formation of the elements that make all of us.

The horizontal rainbows show the spectra for the three objects on the left. The bottom, very compact object is a star in our own Milky Way. The other two objects are an interacting pair of young galaxies, observed as they were 7 billion years ago! We can say this because we see an emission line from hydrogen in both galaxies (indicated with arrows). This emission line allows us to measure the galaxies’ distances.
Galaxy Zoo relatives at AAS meeting – Hubble does overlapping galaxies
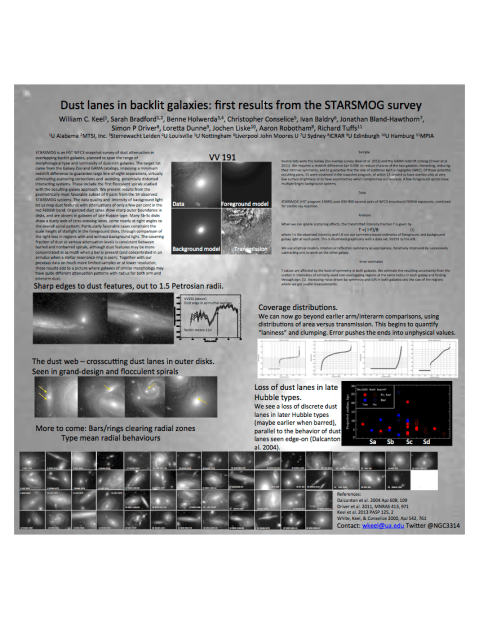
Among the results being presented at this week’s meeting of the American Astronomical Society in Texas (near Dallas) is this poster presentation on the status of the STARSMOG project. This program, a “snapshot” survey using the Hubble Space Telescope, selected targets from a list of overlapping galaxy pairs with spiral members and very different redshifts, so they are not interacting with each there and likely to be more symmetric. The source list includes pairs from Galaxy Zoo (about 60%) and the GAMA (Galaxy And Mass Assembly) survey. These data will allow very extensive analysis; this presentation reads more like a movie trailer in comparison, highlighting only a few results (primarily from the master’s thesis work by Sarah Bradford).
Among the highlights are:
Sharp outer edges to the location of dust lanes in spiral disks.
Distinct dust lanes disappearing for galaxies “late” in the Hubble sequence (Scd-Sd-Sdm-Sm, for those keeping track), maybe happening earlier in the sequence when there is a bar.
The dust web – in the outer disks of some spirals, we see not only dust lanes following the spiral pattern, but additional lanes cutting almost perpendicular to them. This is not completely new, but we can measure the dust more accurately with backlighting where the galaxy’s own light does not dilute its effects.
A first look at the fraction of area in the backlit regions with various levels of transmitted light. This goes beyond our earlier arm/interam distinction to provide a more rigorous description of the dust distributions.
Bars and rings sweeping adjacent disk regions nearly free of dust (didn’t have room for a separate image on that, although the whole sample is shown in tiny versions across the bottom)
Here is a PNG of the poster. It doesn’t do the images justice, but the text is (just) legible.

{kind=link}